Музыка, написанная нейронной сетью » TrunoV SergeY СommunitY
Искусственный интеллект все больше входит в нашу жизнь — управляет машинами, ставит диагноз в медицине, ставит маты шахматистам. Теперь он добрался до творчества: альбом «Hello World» — это первый сборник музыки, написанной на основе технологий нейронной сети от компании Sony. Эра человеческих талантов подошла к концу или же не всё так просто?
В пятницу, 12 января, была отмечена дата первого музыкального релиза от проекта «Flow Machines». Известный французский композитор Бенуа Карре издал 15-трековый поп-альбом под названием «Hello World» — символичный знак, традиционно используемый программистами при создании программ. «Hello World» — это совместная работа множества музыкантов, в том числе канадского народного артиста Курия Кристмонстса, бельгийской звуковой студии Bionix и номинанта на премию Меркьюри музыканта С. Дюкана и… искусственного интеллекта, который создал все песни из данного альбома!
ИИ все больше ассоциируется с модернизмом и с дополнительным стимулом для творчества. В то время, когда сложный искусственный интеллект являлся лишь спекулятивной особенностью научной фантастики, мало кто думал, что все это воплотится в реальность — теперь «он» управляет нашими автомобилями, помогает дать точный медицинский диагноз или одерживает победу в играх (к примеру, в шахматах). Ко всему этому, теперь он добрался до творчества. Исследовательский проект Flow Machines, является результатом совместной работы научно-компьютерных лабораторий фирмы Sony (в Париже) — это одна из немногих компаний, изучающая возможность использования искусственных алгоритмов для создания музыки.
Программное обеспечение в проекте Flow Machines (предназначенное для машинного обучения), уникально в своей способности создавать сложные результаты, которые могут служить для решения задач, построения прогнозов или быть рекомендациями в узконаправленных областях исследования. Все это основывается на шаблонах, которые получаются путем изучения и обработки больших баз данных. В случае с проектом Flow Machines, запуск которого состоялся в 2012 году, возглавляемый исследователем ИИ Франсуа Пашетом, были получены шаблоны из 13 000 песен, благодаря чему можно было получить определенные статистические модели, которые представляют информацию о том, какой характерной структурой обладает скопление «кирпичиков музыки»: ноты и аккорды при разных стилях музыки. Эти статистические модели затем используются для создания новых мелодических и гармонических последовательностей в нужном стиле, выступая в качестве идей для музыкантов, использующих данное программное обеспечение во время сочинения.
«Идея состоит в том, что, когда артист использует данный ИИ, первое, что он должен сделать это решить, набором каких песен он хочет, чтобы искусственный разум был вдохновлен. Причем, это может быть, как сама песня в целом, так и определенные ноты или пассажи
Карре и Паше утверждают, что «Flow Machines» является логическим следующим этапом развития музыкальной истории человечества. На вечеринке в честь альбома «Hello World» в Париже можно было наблюдать интересные плакаты с вехами из истории музыкальных технологий, таких как появление пифагорейского строя или появление DAW. Это было сделано намерено, чтобы подчеркнуть неизбежность формирования новой эпохи музыки, основанной на искусственном интеллекте. Этот же момент заставил посетителей задуматься над тем: «А кем является композитор по сути?». «Кто такой музыкант?» — как бы в помощь глаголила надпись на стене. « Мы входим в новое направление музыкальных технологий, которое предоставит человечеству эпоху музыки, невозможную ранее — теперь её сможет сочинять каждый человек без музыкального дара и образования», — ответил Паше.
Именно этот акцент на демократизацию музыки и устаревание прежних форм музицирования был основой разговоров оставшегося вечера. Там же, под конец был предоставлен учебник «для начинающих» по работе с «Flow Machines». Его презентация была с предварительным прослушиванием одной из песен из альбома «Hello World». Нам пояснили, что каждый трек был создан ИИ под контролем музыканта, на основании вкуса которого создавалась композиция.
Какой можно сделать вывод от прослушанного? Ну, во-первых, ИИ сочиняет не лучше своих «родственников-композиторов» с радио, хотя они и не обладают искусственной алгоритмизацией. Было ясно видно (или слышно), что Карре был инициатором основной структуры каждой песни, но аранжировка их была все равно неудобно искусственной. Такие треки как «One Note Samba», «Magic Man» и «Mafia Love — 16 Bits», исполнялись вроде бы обычным поп-вокалом, но явно чувствовалась кривая реализация, полная искажений, резких прерываний на основе искусственной алгоритмизации. Все это слушалось не как «новое и инновационное», а как неуклюжее и странное.
Если алгоритм «Flow Machines» разработан как творческий инструмент для композиторов и музыкантов, то это только первые шаги. «Hello World», конечно, необычен в своем «алгоритмическом подходе» к созданию композиции, но сама музыка — это всего лишь стандартная попсятина. И хотя это направление музыки, созданное искусственным интеллектом, в настоящее время не является ни благом, ни проклятием для музыкантов, она все же вызывает серьезные вопросы о будущем: « Как слушатели должны относиться к музыке, создаваемой ИИ? В какой момент эти алгоритмы смогут сделать хотя бы один «хит»? В газете «The Guardian» консультант по музыкальной индустрии Марк Маллиган предположил, что музыка ИИ не является мерилом качества музыки. «Пока вы правильно подходите к композиторству и используете ИИ для помощи в творчестве, то от этого никаких проблем не будет — все только в плюс вам», — заявил он.
Многие фирмы заинтересованы в данном направлении развития — это связано с проблемами авторских прав. К примеру, Flow Machines публично связан с Spotify, можно предположить, что если пользователи будут добавлять плейлисты с музыкой, созданной на основе искусственной алгоритмизации, то компания может не платить деньги за авторские права после публикации такой музыки. Отвечая на вопрос о правовых процедурах авторского права, связанных с производством «Hello World», Паше просто ответил: «
Трудно выбросить из головы мысли о неблагоприятных последствиях ИИ в музыке. Но на протяжении еще последующего десятилетия в этом направлении будет мало какого-либо основательного продвижения, если даже через несколько годков появится программа, которая сможет на высоком уровне создавать музыку, то она все равно будет работать только в определенных музыкальных направлениях. На данный момент музыка от ИИ — это новинка и, как минимум, креативный инструмент для композиторов. Паше и Карре планируют выпуск второго альбома на своем лейбле «Flow Records». «Следующие треки уже не будут такими как эти», — сказал Паше. «Там будет другой стиль. Мы больше времени уделим мелодиям и оркестровой аранжировке. Может быть, третий альбом будет вообще в стиле рэпа. Посмотрим
».Если вам понравилась статья, то попрошу репосты или лайки. Для меня это будет хорошей поддержкой.
Наше сообщество в Контакте Твиттере Фэйсбуке Ютубе Дзен
Материал является авторским, при копировании ссылка на статью или сайт sergeitrunov.ru обязательна!
Поделиться ссылкой:
Понравилось это:
Нравится Загрузка…
Похожее
sergeitrunov.ru
Генерация классической музыки с помощью рекуррентной нейросети / Хабр
В наше время обучаемые нейросети творят удивительные вещи, но эксперименты в этой области продолжают открывать нечто новое. Например, программист Даниэль Джонсон (Daniel Johnson) опубликовал результаты своих экспериментов по применению нейросетей для генерации классической музыки.К сожалению, на GT нельзя встроить аудиофайл, поэтому приходится давать прямую ссылку, чтобы послушать один из результатов: http://hexahedria.com/files/nnet_music_2.mp3.
Как у него это получилось?
Даниэль Джонсон говорит, что основное внимание уделил такому свойству как инвариантность. Большинство существующих нейросетей для генерации музыки инвариантны по времени, но не инвариантны по нотам. Поэтому транспонирование всего на один шаг приведет к совершенно другому результату. Для большинства других применений такой подход хорошо работает, но не в музыке. Здесь хотелось бы достичь гармонии созвучий.
Даниэль нашел только один тип популярных нейросетей, где есть инвариантность по нескольким направлениям: это сверточные нейронные сети для распознавания изображений.

Автор адаптировал сверточную модель, добавив для каждого пикселя рекуррентную нейросеть с собственной памятью, и заменив пиксели на ноты. Таким образом, он получил систему, которая инвариантна и по времени, и по нотам.
Но в такой сети нет механизма получения гармоничных аккордов: на выходе каждая нота совершенно независима от других.
Чтобы добиться сочетания нот, Джонсон использовал модель типа RNN-RBM, где одна часть нейросети отвечает за время, а другая часть — за созвучные аккорды. Чтобы обойти ограничения RBM, он придумал внедрить две оси: для времени и для нот (и псевдоось для направления вычислений).

С помощью библиотеки Theano автор сгенерировал нейросеть по своей модели. Первый слой с осью по времени принимал на входе следующие параметры: позиция, высота звука, значение окружающих нот, предыдущий контекст, ритм. Затем срабатывали самогенерирующие блоки на основе кратко-долговременной памяти (LSTM): в одном рекуррентные соединения направлены по оси времени, в другом — по оси нот. После завершающего блока LSTM находится простой нерекуррентный слой для выдачи конечного результата, у него два значения на выходе: вероятность воспроизведения для конкретной ноты и вероятность артикуляции (то есть вероятность того, что нота будет сочетаться с другой).
Во время тренировки использовался случайным образом выбранный набор коротких музыкальных фрагментов из MIDI-коллекции Classical Piano Midi Page. Затем слегка поиграли с логарифмами, чтобы параметр кросс-энтропии на выдаче был хотя бы не слишком низким. Для гарантированной специализации слоев применили такой прием как
Практическая модель состояла из двух скрытых слоев по времени, каждый из 300 узлов, и двух слоев по оси нот, на 100 и 50 узлов, соответственно. Тренировка проводилась в виртуальной машине g2.2xlarge в облаке Amazon Web Services.
Результаты
Исходный код программы опубликован на Github.
habr.com
Стилизация музыки с помощью нейросетей / Блог компании Mail.Ru Group / Хабр

За последнее десятилетие глубокие нейросети (Deep Neural Networks, DNN) превратились в превосходный инструмент для ряда ИИ-задач вроде классификации изображений, распознавания речи и даже участия в играх. По мере того, как разработчики пытались показать, чем обусловлен успех DNN в сфере классификации изображений, и создавали инструменты для визуализации (например, Deep Dream, Filters), помогающие понять, «что» именно «изучает» DNN-модель, возникло новое интересное применение: извлечение «стиля» из одного изображения и применение к другому, иного содержания. Это назвали «переносом визуального стиля» (image style transfer).

Слева: изображение с полезным содержимым, в центре: изображение со стилем, справа: содержимое + стиль (источник: Google Research Blog)
Это не только всколыхнуло интерес многих других исследователей (например, 1 и 2), но и привело к появлению нескольких успешных мобильных приложений. За последние пару лет эти методы переноса визуального стиля сильно улучшились.

Перенос стиля от Adobe (источник: Engadget)

Пример с сайта Prisma
Короткое введение в работу подобных алгоритмов:
Однако несмотря на достижения в работе с изображениями, применение этих методик в других областях, например, для обработки музыки, было весьма ограниченным (см. 3 и 4), а результаты вовсе не такие впечатляющие, как в случае с изображениями. Это наводит на мысль, что в музыке переносить стиль гораздо сложнее. В этой статье мы рассмотрим задачу подробнее и обсудим некоторые возможные подходы.
Почему так трудно переносить стиль в музыке?
Давайте сначала ответим на вопрос: что такое «перенос стиля» в музыке? Ответ вовсе не так очевиден. В изображениях концепции «содержимого» и «стиля» интуитивно понятны. «Содержимое изображения» описывает представленные объекты, например, собак, дома, лица и так далее, а под «стилем изображения» понимаются цвета, освещение, мазки кисти и текстура.
Однако музыка по своей природе семантически абстрактна и многомерна. «Содержимое музыки» может означать разные вещи в разных контекстах. Зачастую содержимое музыки ассоциируется с мелодией, а стиль — с аранжировкой или гармонизацией. Однако содержимым может быть и текст песни, а разные мелодии, использованные для пения, можно интерпретировать как разные стили. В классической музыке содержимым можно считать партитуру (включающую в себя и гармонизацию), в то время как стилем будет интерпретация нот исполнителем, который привносит свою собственную экспрессию (варьируя и добавляя от себя какие-то звуки). Чтобы лучше понять суть переноса стиля в музыке, посмотрите пару этих видео:
Во втором ролике использованы различные методики машинного обучения.
Итак, перенос стиля в музыке по определению трудно формализовать. Есть и другие ключевые факторы, усложняющие задачу:
- Машины ПЛОХО понимают музыку (пока): успех в переносе стиля в изображениях проистекает из успеха DNN в задачах, связанных с пониманием изображений, например, распознавании объектов. Поскольку DNN могут разучивать свойства, меняющиеся у разных объектов, то методики обратного распространения (back-propagation) могут использоваться для изменения целевого изображения, чтобы оно соответствовало свойствам содержимого. Хотя мы достигли значительного прогресса в создании моделей на основе DNN, способных разбираться в музыкальных задачах (например, транскрибирование мелодии, определение жанра и тому подобное), нам ещё далеко до высот, достигнутых в обработке изображений. Это серьёзное препятствие для переноса стиля в музыке. Имеющиеся модели просто не могут разучить «прекрасные» свойства, позволяющие классифицировать музыку, а значит прямое применение алгоритмов переноса стиля, используемых при работе с изображениями, не даёт такого же результата.
- Музыка скоротечна: это данные, представляющие собой динамические ряды, то есть музыкальный фрагмент изменяется со временем. Это усложняет обучение. И хотя рекуррентные нейросети и LSTM (Long Short-Term Memory, долгая краткосрочная память) позволяют эффективнее обучаться на скоротечных данных, нам ещё предстоит создать надёжные модели, способные научиться воспроизводить долгосрочную структуру музыки (примечание: это актуальное направление исследований, и учёные из команды Google Magenta добились в этом некоторого успеха).
- Музыка дискретна (как минимум на символьном уровне): символьная, или записанная на бумаге музыка по своей природе дискретна. В равномерно темперированном строе, наиболее популярной сегодня системе настройки музыкальных инструментов, звуковые тоны занимают дискретные позиции на непрерывной шкале частот. При этом длительность тонов тоже лежит в дискретном пространстве (обычно выделяют четвертные тоны, полные тоны и так далее). Поэтому очень сложно адаптировать пиксельные методы обратного распространения (используемые для работы с изображениями) в сфере символьной музыки.

Дискретная природа музыкальных нот в равномерно темперированном строе.
Следовательно, методики, используемые для переноса стиля в изображениях, не применимы в музыке напрямую. Для этого их нужно переработать с акцентом на музыкальные концепции и идеи.
Для чего нужен перенос стиля в музыке?
Зачем вообще нужно решать эту задачу? Как и в случае с изображениями, потенциальные применения переноса стиля в музыке довольно интересны. Например, разработка инструмента в помощь композиторам. Скажем, автоматический инструмент, способный трансформировать мелодию с использованием аранжировок из разных жанров, будет крайне полезен для композиторов, которым нужно быстро попробовать разные идеи. Заинтересуются такими инструментами и диджеи.
Косвенным результатом подобных изысканий будет значительное улучшение систем музыкальной информатики. Как пояснялось выше, чтобы в музыке работал перенос стиля, создаваемые нами модели должны научиться лучше «понимать» разные аспекты.
Упрощение задачи переноса стиля в музыке
Начнём с очень простой задачи по анализу монофонических мелодий в разных жанрах. Монофонические мелодии — это последовательности нот, каждая из которых определяется тоном и длительностью. Тоновая прогрессия по большей части зависит от звукоряда мелодии, а прогрессия длительности зависит от ритма. Так что сначала чётко разделим «тоновое содержимое» (pitch content) и «ритмовый стиль» (rhythmic style) в качестве двух сущностей, с помощью которых можно перефразировать задачу переноса стиля. Также при работе с монофоническими мелодиями мы сейчас будем избегать задач, связанных с аранжировкой и текстом.
В отсутствие заранее обученных моделей, способных успешно различать тоновые прогрессии и ритмы монофонических мелодий, мы сначала прибегнем к очень простому подходу к переносу стиля. Вместо того, чтобы пытаться изменить тоновое содержимое, выученное на целевой мелодии, ритмовым стилем, выученным на целевом ритме, мы попытаемся по отдельности обучить паттернам тонов и длительностей из разных жанров, а затем попробуем объединить их. Примерная схема подхода:

Схема метода межжанрового переноса стиля.
Обучаем отдельно тоновым и ритмовым прогрессиям
Представление данных
Мы представим монофонические мелодии как последовательность музыкальных нот, каждая из которых имеет индекс тона и последовательности. Чтобы наш ключ представления был независимым, воспользуемся представлением на основе интервалов: тон следующей ноты будет представлен как отклонение (± полутоны) от тона предыдущей ноты. Создадим два словаря для тонов и длительностей, в которых каждому дискретному состоянию (для тона: +1, -1, +2, -2 и так далее; для длительностей: четверть ноты, полная нота, четверть с точкой и так далее) присвоен индекс словаря.

Представление данных.
Архитектура модели
Воспользуемся такой же архитектурой, которую использовали Коломбо с коллегами — они одновременно обучали две LSTM-нейросети одному музыкальному жанру: а) тоновая сеть училась предсказывать следующий тон на основе предыдущей ноты и предыдущей длительности, б) сеть длительностей училась предсказывать следующую длительность на основе следующей ноты и предыдущей длительности. Также перед LSTM-сетями мы добавим уровни встраивания (embedding layer) для сопоставления индексов входных тона и длительности в заучиваемых пространствах встраивания. Архитектура нейросети показана на картинке:

Процедура обучения
По каждому жанру сети, отвечающие за тоны и длительности, обучаются одновременно. Мы воспользуемся двумя датасетами: a) Norbeck Folk Dataset, охватывающий около 2000 ирландских и шведских народных мелодий, б) джазовый датасет (публично не доступен), охватывающий около 500 джазовых мелодий.
Слияние обученных моделей
При тестировании мелодия сначала генерируется с помощью тоновой сети и сети длительностей, обученных на первом жанре (допустим, фолк). Затем последовательность тонов из сгенерированной мелодии используется на входе для сети последовательностей, обученной на другом жанре (скажем, джазе), и в результате получается новая последовательность длительностей. Следовательно, мелодия, созданная с помощью комбинации двух нейросетей, имеет последовательность тонов, соответствующей первому жанру (фолк), и последовательность длительностей, соответствующих второму жанру (джаз).
Предварительные результаты
Короткие отрывки из некоторых получившихся мелодий:
Фолк-тоны и фолк-длительности
Выдержка из нотной записи.
Фолк-тоны и джаз-длительности
Выдержка из нотной записи.
Джаз-тоны и джаз-последовательности
Выдержка из нотной записи.
Джаз-тоны и фолк-последовательности
Выдержка из нотной записи.
Заключение
Хотя текущий алгоритм неплох для начала, у него есть ряд критических недостатков:
- Невозможно «перенести стиль» на основе конкретной целевой мелодии. Модели обучаются паттернам тонов и длительностей на жанре, а значит все трансформации определяются жанром. Было бы идеально изменять музыкальный фрагмент в стиле конкретной целевой песни или фрагмента.
- Невозможно управлять степенью изменения стиля. Был бы очень интересно получить «ручку», управляющую этим аспектом.
- При слиянии жанров невозможно сохранить музыкальную структуру в трансформированной мелодии. Долгосрочная структура важна для музыкальной оценки в целом, а чтобы сгенерированные мелодии были музыкально эстетичны, структура должна сохраняться.
В следующих статьях мы рассмотрим способы обхода этих недостатков.
habr.com
Нейросеть «Яндекса» записала альбом в стиле группы Nirvana

Не так давно нейросеть отечественной компании «Яндекс» записала альбом в стиле группы «Гражданская оборона». Многие расценили это как единичный случай для привлечения внимания к разработкам компании. Но, как оказалось, после записи на русском языке программисты пошли еще дальше и переключились на зарубежные группы. К примеру, буквально на днях было записано несколько треков в стиле американской рок-группы Nirvana.
За прошедшее время программисты «Яндекса» Иван Ямщиков (который на данный момент работает в Институте научной математики Общества Макса Планка в Лейпциге) и Алексей Тихонов научили свою нейронную сеть сочинять стихи на английском языке, похожие на тексты песен Курта Кобейна, лидера всемирно известного коллектива. Первый альбом нейросети в стиле группы «Гражданская оборона» был записан при помощи профессиональных музыкантов и носил название «Нейронная оборона». По аналогии с предыдущим проектом, к работе над записью альбома в стиле группы Nirvana привлекли профессионального американского музыканта Роба Кэррола, поклонника творчества Курта Кобейна и его рок-группы. А сам альбом получил название «Neurona».
Для того чтобы обучить нейросеть писать стихи на английском языке, Ивану Ямщикову пришлось собрать огромный архив современной и классической зарубежной поэзии общим объемом около 200 мегабайт. В ходе работы выяснилось, что научить нейросеть языку Шекспира гораздо сложнее, чем русскому. Дело в том, что в англоязычной поэзии гораздо меньше четко установленных правил и там не всегда работает «нормальная» грамматика. Поэтому команде экспертов пришлось удалить часть текстов из архива. После того как полученный результат удовлетворил ученых, они записали треки на старую аудиокассету с альбомом группы Nirvana. Финальный результат выложили в Сеть и даже опубликовали клип на одну из песен в YouTube. Как заверяют разработчики, алгоритмы работы нейросети и детали ее разработки будут в ближайшее время опубликованы в одном из научных журналов. Кроме того, российскому изданию РИА «Новости» удалось взять интервью у Ивана Ямщикова, полный текст которого, а также клип на один из треков за авторством нейросети вы можете найти ниже.
Иван, учитывая сложности, с которыми вы сталкивались при создании «Нейроны», пробовали ли вы сделать нечто похожее для текстов певицы Линды, известной необычным стилем своих стихов?
Год назад мы обучили нейросеть генерировать тексты в стиле Егора Летова. В принципе, ничто не мешает научить ее генерировать тексты и в стиле Линды.
Если нейросети тепер
hi-news.ru
Формирование музыкальных предпочтений у нейронной сети — эксперимент по созданию умного плеера
Данная статья посвящена работе по исследованию возможности обучить простейшую (относительно) нейронную сеть «слушать» музыку и отличать «хорошую» по мнению слушателя от «плохой».Цель
Научить нейронную сеть отличать «плохую» музыку от «хорошей» или показать, что нейронная сеть на это неспособна (данная конкретная ее реализация).
Этап первый: нормализация данных
Учитывая что музыка это совокупность несчетного числа звуков просто так «скормить» ее нейронной сети не выйдет, соответственно нужно определить что именно сеть будет «слушать». Вариантов выделения из музыки «наиболее важных» особенностей бесконечное множество. Нужно определить что потребуется выделить из музыки. В качестве опорных данных я определил, что выделить нужно некоторое представление о частотах звуков используемых в музыке.
Я решил выделить именно частоты, т.к. во первых они различны для разных музыкальных инструментов.

Во вторых чувствительность слуха в зависимости от частоты различна и достаточно индивидуальна (в разумных пределах).

В третьих насыщенность трека определенными частотами достаточно индивидуальна, но при этом схожа для схожих композиций, к примеру соло на гитаре в двух различных, но похожих треках будет давать схожую картину «насыщенности» трека на уровне отдельных частот.
Таким образом задача нормализации сводится к выделению некоторой информации о частотах, которая показывает:
- как часто в композиции звучит звук из данного диапазона частот
- как громко он звучал
- как долго он звучал
- и так для каждого определенного диапазона частот (нужно разбить весь «слышимый» спектр на определенное число диапазонов).
Для выделения частотной насыщенности в треке на каждом временном интервале можно воспользоваться данными FFT, эти данные можно при желании вычислить вручную, но я воспользуюсь уже готовой открытой библиотекой Bass, точнее оболочкой для нее Bass.NET, которая позволяет получить эти данные более гуманно.
Для получения FFT данных с трека достаточно написать небольшую функцию.
После получения сырых данных необходимо их обработать.

Визуализация полученных данных
Во первых нужно определить на сколько частотных диапазонов делить искомый звук, от этого параметра зависит то насколько детализированным будет результат анализа, но и соответственно даст большую нагрузку на нейронную сеть (ей потребуется больше нейронов, чтобы оперировать большими данными). Для нашей задачи возьмем 1024 градации, это достаточно детальный спектр частот и сравнительно небольшое количество информации на выходе. Теперь необходимо определить как из N массивов float[] получить 1 массив, который содержит более менее всю необходимую нам информацию: насыщенность звука определенными спектрами, частота возникновения различных спектров звука, его громкость, его длительность.
С первым параметром «насыщенностью» все достаточно просто, можно просто просуммировать все массивы и на выходе мы получим как «много» было каждого спектра во всем треке, но это не будет отражать других параметров.
Чтобы «отразить» на конечном массиве и другие параметры можно суммировать немного сложней, не буду вдаваться в подробности реализации подобной «суммирующей» функции, т.к. число ее возможных реализаций фактически бесконечно.
Графическое представление полученного массива:
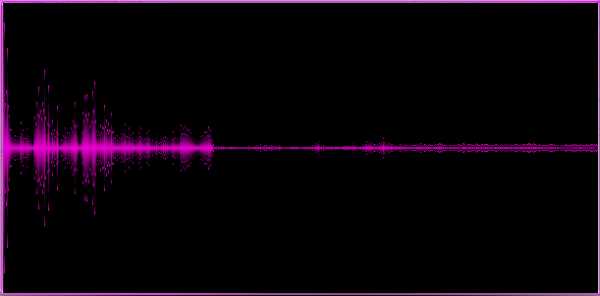
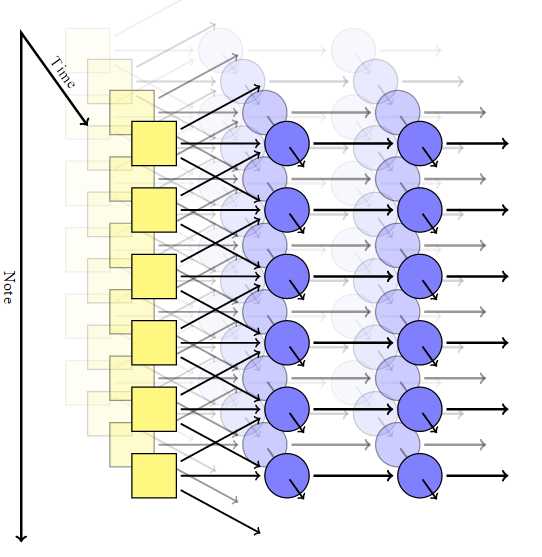
Пример 1. Относительно спокойная мелодия с элементами легкого рока, рояль и вокал

Пример 2. Относительно «мягкий» dubstep с элементами отшкребания мозга от стен не очень мягкого dubstep

Пример 3. Музыка в стиле близком к trance

Пример 4. Pink Floyd

Пример 5. Van Halen
Пример 6. Гимн России
На приведенных примерах становится видно, что различные жанры дают различные «спектральные картины», это хорошо, значит мы выделили по крайней мере некоторые ключевые особенности трека.
Теперь нужно подготовить нейронную сеть, которую будем «обучать». Алгоритмов нейронных сетей много, часть лучше для определенных задач, часть хуже, я не ставлю цели изучить в контексте задачи все виды, я возьму первую попавшуюся под руку ее реализацию (спасибо dr.kernel), достаточно гибкую, чтобы ее приспособить к решению поставленной задачи. Я не выбираю «более подходящую» нейронную сеть, т.к. задача проверить «нейронную сеть» и если случайная ее реализация покажет хороший результат, то однозначно есть более подходящие виды нейронных сетей, что покажут результаты еще лучше, если же сеть не справится, то это покажет только, что данная нейронная сеть не справилась с задачей.
Данная нейронная сеть обучается данными, которые лежат в диапазоне от 0 до 1 и на выходе тоже дает значения от 0 до 1. Поэтому данные нужно привести к «пригодному виду». Привести данные к подходящему виду можно множеством способов, результат все равно будет похожий.
Этап второй: подготовка нейронной сети
Нейронная сеть, которую я использую определяется количеством слоев, количеством входных, выходных и количеством нейронов на каждом слое.

Очевидно, что не все конфигурации «одинаково полезны», но определенных методов для определения «лучшей» конфигурации для данной задачи мне неизвестны, если таковые вообще могут быть. Можно было бы просто попробовать несколько различных конфигураций и остановиться на той «что лучше подходит», но я пойду иным путем, я буду выращивать нейронную сеть эволюционным алгоритмом, позже в статье объясню как именно.
К данному моменту определены формат входных данных, нужно определить формат выходных данных. Очевидно можно просто делить треки на «хорошие» и «плохие» и будет достаточно 1 выходного нейрона, но я считаю, что хорошие и плохие понятие растяжимое, в частности определенная музыка лучше подходит для пробуждения утром, другая прогулки по городу по дороге на работу, третья для отдыха вечером после работы и т.д. то есть качество трека должно определяться еще и относительно времени суток и дня недели, итого 24*7 выходных нейронов.
Теперь нужно определить выборку для обучения, для этого можно конечно взять все треки и сидеть отмечать в какое время их хочется послушать или лучше вообще никогда не слышать, но я не из тех кто бы сидел часами и отмечал треки, гораздо проще это сделать «по ходу пьесы», то есть во время прослушивания трека. То есть «обучающую» выборку должен сформировать плеер, во время прослушивания треков в котором можно было бы отметить трек «хорошим» или «плохим». И так представим, что такой плеер есть (он действительно есть, то есть был написан на основе открытых кодов другого плеера). После десятка часов прослушивания музыки в различные дни собираются данные для первой выборки. Каждый элемент выборки содержит входные данные (1024 значения спектральной картины трека) и выходные (24*7 значений от 0 до 1, где 0 совсем плохой трек и 1 очень хороший трек для каждого часа из 7 дней недели). При этом при отметке «хороший» трек + ставился на всех днях недели и часах, но в данный час\день недели +был больше, и аналогично для «плохой», то есть данные не 0 и 1, а некоторые значения между 0 и 1.
Данные для обучения есть, теперь нужно определить что считать обученной сетью, в данном случае можно считать, что для загруженных в нее данных отличие между откликом сети на входные данные не должно и исходными выходными данными должно быть минимально. Так же крайне важна возможность сети «предсказывать» по неизвестным ей данным, то есть не должна быть переобучена, с переобученной сети толку будет мало. Определить «качество отклика» проблем нет, для этого есть функция вычисляющая ошибку, остается вопрос как определить качество предсказания. Для решения этой проблемы достаточно обучать сеть на 1 выборке, но проверять качество на другой, при этом выборки должны быть случайны и элементы первой и второй не должны повторяться.
Алгоритм проверки уровня обучения сети найден, теперь нужно определить ее конфигурацию. Как я уже говорил для этого будет использоваться эволюционный алгоритм. Для этого возьмем стартовую конфигурацию, скажем 10 слоев, в каждом по 100 нейронов (этого будет однозначно мало и качество такой сети будет не очень хорошим), далее обучим за определенное число шагов (скажем 1000), после определим качество ее обучения. Далее переходим к «эволюции», создаем 10 конфигураций, каждая из которых является «мутантом» исходной, то есть у нее изменена в случайную сторону либо количество слоев, либо количество нейронов на каждом или некоторых слоях. Далее обучаем каждую конфигурацию тем же способом, что и исходную, выбираем лучшую из них и определяем ее как исходную. Данный процесс продолжаем до тех пор, пока не наступает такой момент, что мы не можем найти конфигурацию, которая обучается лучше чем исходная. Данную конфигурацию считаем лучшей, она оказалась способной лучше всех «запомнить» исходные данные и лучше всех предсказывает, то есть результат ее обучения наиболее качественный из возможных.
Эволюционный процесс занял порядка 6 часов для выборки размером в 6000 элементов, после пары часов оптимизаций процесс занимает около 30 минут, конфигурация может отличаться в различных выборках, но чаще всего конфигурация примерно из 7 слоев, с количеством нейронов плавно увеличивающихся к 3-4 слою и далее более быстро сокращается к последнему слою, своеобразный горб на 3-4 слое из 7, по всей видимости такая конфигурация наиболее «способная» для данной сети.
Итак сеть «выросла» и способна к обучения, начинается обычное для сети обучение, долгое и нудное (до 15 минут), после сеть готова «слушать музыку» и говорить «плохая» она или «хорошая».
Этап третий: сбор результатов
Вес «мозга» — конфигурации обученной сети составил 25 мб, вес будет различаться для различных выборок, в целом чем больше выборка тем больше нужно нейронов, чтобы справиться с ней, но вес среднестатистической сети будет примерно таким же.
Обучающая выборка состояла из «хороших» по моему скромному мнению треков, таких как Van Halen, Pink Floyd, классическая музыка (не любая), легкий рок, мелодичные и спокойные треки. «Плохой» в выборке по моему мнению считались реп, попса, слишком тяжелый рок.
Определим «индекс качества» случайных треков, который посчитает нейронная сеть после обучения.
- Van Halen — 29 pts
- Rammstein-Mutter(альбом) — 20-23 pts
- Rihanna — 26 pts
- The Punisher -11-17 pts
- Radiorama — 25 pts
- R Claudermann — 25-29 pts
- The Gregorians — 27-29 pts
- Pink Floyd — 29-33 pts
- Русский «рэп» низкого качества — 9-11 pts
- Красная плесень 16-19 pts
- Би-2 24-29 pts
- Високосный год — 25-33 pts
Вывод:
Первая попавшаяся нейронная сеть, после «эволюционной» настройки конфигурации и обучения показала наличие «навыков» определения характеристик трека. Нейронная сеть может быть научена «слушать музыку» и отделять треки, которые понравятся или не понравятся «слушателю», который ее обучал.
Полный исходный код приложения на C# и скомпилированную версию можно скачать на GitHub или через Sync.
Внешний вид приложения, в котором реализован весь описанный в статье функционал:
Надеюсь, мой опыт в данном исследовании поможет в будущем тем, кто захочет изучить возможности нейронных сетей.
habr.com
Как нейросеть научилась подражать Кобейну и Скрябину и к чему это приведет — The Village
В понедельник в Сети появился первый альбом группы Neurona — EP из четырех треков в жанре, сформулированном на «Яндекс.Музыке» как «альтернатива». За дебютом стоят американский вокалист Роб Кэррол и разработчики Иван Ямщиков и Алексей Тихонов. А предложенная ими альтернатива — почти альтернатива поэту — нейросеть, научившаяся писать стихи в духе лирики Курта Кобейна.
Это уже третий музыкально-алгоритмический эксперимент Ивана и Алексея после «Нейронной обороны» — вариации нейросети на тему творчества Егора Летова — и композиции, написанной алгоритмом в стиле работ Скрябина и исполненной камерным оркестром на Yet another Conference. Когда оркестр, открывавший конференцию о применении новейших цифровых технологий в различных областях, смолк, на сцене появился Андрей Себрант и с видом очень сосредоточенным заявил: «То, что вы видели, — не просто метафора, а пример того, как изменилась наша жизнь с момента появления машинного интеллекта».
The Village выяснил у специалистов, что все это значит и к чему приведет.
Нейросети рисуют котов, ищут людей по фотографии, верстают сайты, переводят тексты и наконец читают рэп, пишут песни и музыку. Но прежде чем рассказать, как они это делают и какое будущее ждет музыкальную индустрию и индустрию развлечений с развитием нейросетей, важно прояснить пару базовых деталей.
Нейросеть — это тип алгоритма, вид машинного обучения, не более того. Никакого антропоморфного робота, возникающего в сознании большинства людей, когда они видят очередной броский заголовок, что нейросеть или искусственный интеллект опять что-то сделал, нет. «Если говорить очень просто, то машинное обучение — это обучение алгоритмов работать на основе данных, которые им показывают, — объясняет Михаил Биленко, руководитель управления машинного интеллекта и исследований „Яндекса“. — Представьте, что вам нужно научить программу отличать кошек от собак на фотографии. Благодаря машинному обучению сейчас можно просто показать алгоритму набор картинок с кошками и набор картинок с собаками, и на основе этой информации он научится определять кошек и собак и на других картинках, которых не было в этих наборах. А нейросети — это просто один из видов машинного обучения, который крайне эффективно решает определенные классы задач».
Самое первое предположение о том, что машина может писать музыку, выдвинула автор идеи компьютера, математик Ада Лавлейс в 1843 году, а задачу сделать алгоритм, который бы моделировал собой мозг, ученые поставили перед собой в начале 60-х. Раз мозг сочиняет музыку, возможно, и алгоритм с такой задачей справится. Если же говорить о качественном прорыве в развитии нейросетей, позволившем научить их генерировать музыку, то он лежал не в плоскости математики, а в вычислительной стороне дела. И способствовали ему, как ни странно, геймеры 90-х.
«Оказалось, что графические карты, изначально создававшиеся для компьютерных игр, можно использовать для научных вычислений и для обучения нейросетей, поскольку при обучении там происходит параллельно очень много сравнительно простых процессов», — рассказывает Иван Ямщиков, сотрудник Института Макса Планка. Графическая карта в игре разбивает всю поверхность на треугольники, и каждый треугольник обрабатывает отдельно, а потом все склеивает вместе. «В какой-то момент кто-то сказал: „Погодите, а давайте вместо картинок в компьютерных играх другие алгоритмы параллельных вычислений на видеокартах гонять!“ — в итоге сейчас за сравнительно небольшие деньги можно купить устройство, которое лет десять назад считалось бы суперкомпьютером, и на нем сравнительно быстро обучать достаточно глубокие нейросети», — говорит исследователь.
Чтобы научить нейросеть писать музыку, ей нужно дать очень большое количество примеров музыкальных произведений в понятном ей формате — например, партитуры или MIDI-файлы. Обучая сеть писать стилизации под Скрябина, операторы использовали в качестве примеров 4 гигабайта MIDI-файлов с классическими и современными произведениями. Сбор примеров — первая большая проблема нейросетевого композиторства. Заключается она в том, что таких примеров нужно действительно очень много, а для обучения сетки подойдет далеко не каждый файл.
«Например, мы берем простенький хаус-трек с очень скучным монотонным басом, который всю композицию играет одну ноту. Если наша задача сделать музыку как можно более разнообразной, такой трек для обучения использовать не стоит: он сильно испортит качество результата. Все, чему от него научится нейросетка, — повторять одну и ту же ноту», — объясняет Ямщиков.
Поэтому после формирования дата-сета его приходится фильтровать, и определение принципов этой фильтрации — труд на границе между наукой и искусством.
Следующая задача оператора нейросети — определить, какую информацию из выбранного трека нужно передавать и в каком виде. По словам консультанта «Яндекса», есть несколько используемых моделей. Одна из них — автоэнкодер. Это метод, когда нейросеть слушает какой-то фрагмент музыки целиком, а потом должна целиком его воспроизвести, и чем ближе сетка попадает в оригинал, тем лучше. Есть языковая модель — когда сеть слушает одну ноту и пытается предсказать следующую, слушает реальный ответ и опять пытается предсказать следующую ноту. В вопросе подходов на данный момент теории меньше, чем практики, поэтому программисты просто перебирают разные варианты и смотрят, где получается интереснее.
В процессе работы над генерацией музыки Алексей Тихонов натренировал три нейросетки: одна пишет мелодию, одна — бас, и еще одна — барабаны. Такая система в целом больше напоминает прототип панк-группы, чем оркестра, поэтому для классического открытия с камерным оркестром ее использовать не стали. Вместо этого мелодии, написанные нейросетью, отдали Марии Черновой, основателю и креативному директору «Артнови», композитору и эксперту по творчеству Скрябина. Ее задачей было связать написанные нейросетью пьесы в единую композицию и создать аранжировку под утвержденный состав камерного оркестра с сольной партией терменвокса. Первую, более механистичную часть композиции машина на конференции сыграла сама, вторую — аранжированную Черновой — исполняли живые музыканты. И необходимость использовать живых исполнителей обязала внести в генеративную музыку еще ряд изменений. «При сохранении музыкального языка нейросети моя задача также состояла в том, чтобы придать пьесе форму, развитие и логику в гармоническом построении», — уточняет композитор.
Нейросети не только пишут музыку, но и слова, которые можно на нее наложить. В марте 17-летний школьник Робби Бэррат научил нейросеть сочинять рэп по мотивам текстов Канье Уэста, скормив ей 6 тысяч строк из его песен в качестве примеров.
Изначально алгоритм просто менял их местами, но потом стал писать лирику самостоятельно. Алексей Тихонов и Иван Ямщиков учили нейросеть писать тексты в стиле Летова и Кобейна. Первого выбрали из-за свойственной «Гражданской обороне» и всему русскому року высокому уровню апофении: в большинстве текстов жанра отсутствует авторский нарратив. Его в песни привносит рефлексирующий слушатель.
Дело в том, что в ходе работы обнажился еще один пробел на стыке математики и филологии. У машины проблема с сюжетностью, а объяснить ей, что это, некому. «Можно объяснить ей, что такое слово, но очевидно, что сюжет не сводится к слову и даже к предложению, — поясняет Иван Ямщиков. — Мы пытаемся разобраться с этой проблемой уже год, и не мы одни. Инструментов, с помощью которых ее пытаются решить, очень много. Некоторые под это дело поднимают десятки миллионов долларов, но, к сожалению, когда заходишь на их сайты и хочешь что-нибудь „потрогать“, они ничего не показывают».
Жорж Польти еще в конце XIX века вывел теорию о том, что в мире существует всего 36 драматических ситуаций, Борхес и вовсе сократил их число до четырех. Но оператор нейросети на вопрос, сколько их, конечно ли число сюжетов, и если нет, как научить нейросеть писать новые, ответить не может. В этом отношении следующий большой прорыв должен произойти с помощью людей искусства и гуманитариев. Чем лучше они научатся гуманитарные науки формализовать, тем больше шансов у разработчиков создать для них более интересные инструменты.
У нейросетей и музыки большое будущее. Во-первых, нейросети уже применяются фактически во всех музыкальных сервисах от Spotify до «Яндекс.Музыки» — там нейросеть советует пользователям новые треки.
Вообще, всякого рода рекомендательные алгоритмы — это колыбель машинного разума. Множество решений и методов, использующихся в разных приложениях искусственного интеллекта, было изначально придумано именно для алгоритмических рекомендаций. «Есть такая цепочка базз-бордов: сначала все говорили про big data, потом все стали говорить про машинное обучение, а потом — про машинный интеллект и нейросети, — объясняет Иван Ямщиков. — Эта последовательность связана с производственным циклом разного рода айтишных компаний». Сначала они поняли: у них много информации о пользователях, которую нужно хранить, чтобы как-то впоследствии научиться на ней зарабатывать. После того как данных стало достаточно много и на них уже можно было натравливать какие-то более продвинутые алгоритмы, все стали говорить про машинное обучение. А дальше в рамках машинного обучения появились нейросети, как раз обладающие большим преимуществом там, где речь идет о персонализации, вкусах и предпочтениях, и становящиеся все более доступной технологией.
«Сегодня нейросети помогают найти действительно похожие по звучанию треки, благодаря чему наши сервисы уже умеют воспринимать музыку как нечто большее, чем просто комбинацию исполнителя и жанра, — рассказывает Евгений Крофто, руководитель группы анализа музыки в „Яндекс.Музыке“. — Мы анализируем, какие треки пользователи слушают совместно, и обучаем сеть предсказывать их похожесть на основании одного лишь аудиосигнала». Очевидно, что в ближайшее время количество такого рода услуг будет расти вместе с уровнем персонализации рекомендаций.
Год назад о себе заявил русский стартап Mubert — первый онлайн-композитор электронной музыки. Его продукт — свободный от копирайта поток ликвид-фанка, дип-хауса, эмбиента и чилстепа, генерируемый алгоритмом в режиме реального времени. В апреле создатели приложения объявили о разработке версии для бегунов Mubert.Run, которая будет генерировать музыку, поддерживающую ритм атлета во время тренировки. Сейчас они привлекают к работе (на коммерческой основе) продюсеров, создающих музыку в диапазонах 160–180 ударов в минуту, и планируют партнерство с одним из спортивных мейджоров.
Конечно, Mubert своим будущим релизом Америку не откроет, спортивные приложения подготовили обширную почву для интеграции в них генеративной музыки. Например, в 2012 году появилась веселая аудиоигра для спортсменов «Zombies, Run!». Приложение с 200 разными миссиями синхронизировалось с картой местности и во время пробежки посылало в наушники игрока звуки преследующих его зомби, заставляя ускоряться. Больше 3 миллионов установок сделало приложение самой большой по числу участников фитнес-игрой на смартфоне. Также алгоритм мог бы изменять звуковую дорожку в игре, синхронизируясь, например, с пульсом пользователя.
Оксфордский стартап Juckedeck, удостоенный «Каннских львов, генерирует royalty free музыку для рекламы. Здесь за 200 долларов можно купить аудио для коммерческого использования.
Еще одна перспектива буквально двух-трех лет — персонализированная музыка в заведениях. Представьте, что вы чекинетесь на входе в кафе, а как только переступаете его порог, в нем меняется звуковое оформление. То есть алгоритм анализирует всех посетителей места и начинает подстраивать звучащую в нем музыку так, чтобы она нравилась в среднем им всем. Если развивать мысль дальше, возможно, на входе в ночной клуб фейсконтрольщик когда-нибудь будет не только мерить гостей испытующим взглядом, но и просить показать плейлист.
Рынок этот пока фактически свободный, и прийти сюда с новым продуктом может кто угодно, главное — придумать для технологии правильное применение.
Если нейросети освоятся в композиторском деле, то, по мнению Марии Черновой, они вполне смогут вытеснить авторов авангардной, интуитивной музыки или нойза. Но вытеснить музыканта-исполнителя ей не под силу. «Музыкант-исполнитель работает со временем, для человека время — это жизнь, люди его очень тонко ощущают, — размышляет она. — Машина не сможет столь же тонко работать со временем, поскольку интуитивной гибкости ей не достичь. В живом исполнении всегда присутствует доля импровизационности, что и подкупает зрителя, хотя я совсем не исключаю появления робоколлективов».
На самом же деле, перед пишущей музыку нейросетью задачи заменить композитора никто и не ставит. «Обычно мы хотим, чтобы машина делала не то, что мы умеем, а то, чего мы не умеем, — говорит Ямщиков. — Экскаватор не заменяет человека с лопатой, при всей схожести с ним, он может делать принципиально другие вещи. И мы все равно используем человека с лопатой, когда копаем грядки на даче, но, когда нам нужно сделать фундамент для дома, мы используем экскаватор». По его словам, не так интересно, научится ли машина писать музыку, как человек. Интересно другое: сможет ли человек с помощью машины сделать нечто принципиально отличающееся от направлений искусства, уже им созданных.
Обложка: Sergey – Stock.adobe.com
www.the-village.ru
Цифровой слух: как «Яндекс» подбирает музыку под ваше настроение | ForbesLife
В «Яндексе» машинное обучение (в том числе и нейросети) используется повсеместно: оно помогает лучше понимать смысл поисковых запросов пользователей, строить оптимальные маршруты в «Навигаторе», с высочайшей точностью прогнозировать погоду и многое другое. А в технологии «Диско» (от слова discovery), которая находится под капотом «Яндекс.Радио», нейросети помогают находить новую интересную для пользователя музыку и подсказывать песни, которые будут созвучны его настроению.
Настроение в цифрах
«Яндекс.Радио» — сервис, который предлагает выбирать станции под настроение и лайками или дизлайками оценивать звучащую музыку. Чтобы сформировать такие станции на основе одного лишь абстрактного понятия настроения необходима помощь нейросетей. Именно они помогают из миллиона композиций отобрать треки, которые могут звучать на конкретной станции. Для жанрового радио такие треки отобрать довольно легко: достаточно, например, взять наиболее популярные песни в определенном жанре среди слушателей «Яндекс.Музыки» и предложить их пользователю.
Но что делать, если нужно отобрать треки для «весенней» станции? И что вообще понимать под «весенним» треком? На первый взгляд кажется, что ответить на второй вопрос могут только люди, поэтому для начала мы используем собственный сервис «Яндекс.Толока», позволяющий поставить большое количество несложных задач, за выполнение которых пользователи получают деньги. В нем мы просим пользователей сказать, считают ли они какие-то треки из нашей библиотеки весенними, и делаем из этого выборку. После этого в игру вступают нейронные сети, для которых такая выборка служит положительным примером, и каждую песню в ней они раскладывают буквально по кирпичикам. В итоге на основе этой выборки нейросеть способна оценить на соответствие теме и другие треки из нашей библиотеки.
Дальше начинается самое интересное. Когда у нас на руках есть готовая «весенняя» радиостанция, нам уже проще создавать новые подборки музыки, пусть даже и полностью противоположные по настроению: например, осеннюю или дождливую. А все потому, что нейросеть, на самом деле, понимает музыку в очень широком смысле. Настолько, что для человека такое понимание довольно сложно представить. Подкрепленная знанием о музыкальных жанрах и их составляющих частях, она видит даже такие особенности треков, которые мы никогда бы не заметили, но при этом они играют важную роль в создании настроения музыки. И этих особенностей очень и очень много. Жонглируя ими, наша заряженная нейросетями рекомендательная система с каждой новой радиостанцией все точнее определяет настроение треков, а для создания новых радиостанций требуется уже не так много пользовательских определений настроения, как в самом начале (хотя без них все равно не обойтись). Говоря простыми словами, нейросеть по-настоящему понимает, из чего состоит, например, восприятие «дождливости» у человека и может выразить числами то, что мы никогда бы не выразили словами.
Найти похожий
Недавно мы начали предлагать пользователям еще один способ открывать для себя новую музыку. Если вы, например, заслушали до дыр Can’t Believe It исполнителей Flo Rida и Pitbull, «Яндекс.Музыка» может предложить вам песню куда менее известного исполнителя, и она будет похожа не только по жанру, но и по звучанию.
Сама по себе задача поиска акустически похожих треков действительно непростая, потому что понятие «схожести» музыки довольно условно. Для кого-то важно, чтобы был похож вокал, другой услышал интересный музыкальный инструмент, а третьему важен ритм.
Во время разработки технологий компьютерного зрения (те самые технологии, которые понимают, что изображено на картинке) мы в «Яндексе» заметили, что в процессе обучения нейросеть строит некоторое свое внутреннее представление изображения, и похожие представления соответствуют похожим по смыслу изображениям. Например, нейросеть может «разглядеть» в разных картинках белых кошек. Мы решили поступить аналогичным образом с музыкой. Казалось бы, что мешает нам просто брать и сравнивать разные треки: вот тут перед припевом бит ускоряется похожим образом, а здесь такая же партия саксофона в конце? Проблема в том, что музыки в мире много, а это значит, что есть и огромное число параметров, каждый из которых не так очевиден, как наличие в песни саксофонной партии, но при этом не менее важен.
Для решения этой задачи, как и в случае с «Радио», мы использовали метод обучения с учителем. Мы даем нейросети пример: вот это трек Can’t Believe It, его спектрограмма (мощность звукового сигнала в разные отрезки времени) выглядит так, а теперь определи, почему он считается танцевальным. Нейросеть понимает, например, что в какой-то момент в треке много высоких частот звука, а в другой момент, наоборот, преобладают низкие. И она начинает искать в спектрограмме другие такие зависимости. Это могут быть и не совсем понятные нам колебания звука, которые не факт, что действительно определяют наш запрос, а могут быть вполне очевидные вещи (например, смена ритма в середине песни). В итоге нейросеть переводит все эти особенности в цифры, а сами треки получаются представлены относительно небольшим набором чисел (от нескольких десятков до пары тысяч). Математически это представление выглядит как вектор, и теперь нам нужно всего лишь найти другие песни, чьи вектора будут похожи на вектор нашего трека.
Когда у нас есть несколько таких представлений, построенных разными сетями, возникает логичный вопрос, а как нам их сравнивать? Здесь снова не обойтись без помощи человека. Мы предлагаем людям послушать исходный трек и пару похожих, по мнению нейросетей, треков. А затем спрашиваем, какой трек из этой пары больше похож на исходный. После этого мы можем измерить, насколько точно решение алгоритма совпадает с оценкой людей и лучший из алгоритмов внедрить в «Яндекс.Музыку».
Электронный композитор
Разработанные нами на основе нейросетей алгоритмы и похожие разработки других компаний позволяют компьютерам лучше понять, как устроена музыка, и научиться воспринимать ее подобно тому, как это делает человек. Все это в перспективе позволит не только делать более качественные рекомендации в сервисах, но и создавать алгоритмы, которые смогут сочинять музыку. Сложно предсказать точное время появления таких алгоритмов, но сегодня мы уже понимаем, как это может работать. А это уже большое дело. Например, можно пытаться обучить нейронные сети составлять музыку подобно тому, как это делают люди в специальных программах — секвенсорах: выбирать музыкальные сэмплы, составлять из них последовательность, накладывать эффекты, но не генерировать сами исходные звуки. Задача выглядит вполне решаемой, но и для этого все равно понадобится помощь музыкантов: исполнители должны предоставить примеры таких последовательностей с наложенными эффектами, и тогда нейросеть научится генерировать свои треки. Пускай поначалу у них будет не самая сложная структура, но это в любом случае неплохое начало.
Совсем другое дело создавать музыку с нуля: здесь мы опускаемся на иной уровень абстракции, и такой задаче сеть обучить гораздо сложнее. Только представьте: одна секунда звука в виде волны в цифровом виде это 44 100 чисел. И чтобы сочинять музыку, алгоритм должен научиться понимать зависимости между этими числами на разных временных масштабах. Допустим, мы научились генерировать короткие и неплохо звучащие отрывки, но сложить целое произведение из них очень сложно. Иными словами, этюд на фортепьяно и симфония — это большая разница, и до сочинения нейросетями симфоний еще довольно далеко. Зато они уже неплохо справляются с имитацией авторского стиля в текстах песен, что можно увидеть на примере «Нейронной обороны», проекта сотрудников Яндекса, которые научили нейросеть сочинять тексты песен в стиле Егора Летова, а затем положили их на музыку.
В ближайшем будущем мы наверняка увидим еще много проектов, которые будут использовать нейросети и для написания текстов, и для генерации музыки. Сложно сказать, как это повлияет на искусство, но нейросети в составе рекомендательных сервисов на него уже совершенно точно повлияли: сегодня мы совсем иначе слушаем и открываем для себя музыку, этот процесс стал проще и интереснее, и это прекрасно.
www.forbes.ru