Нейронная соната: как искусственный интеллект генерирует музыку
Можно ли автоматизировать творчество и оцифровать музу? Разбираемся, действительно ли нейросети претендуют на создание музыкальных шедевров
Об эксперте: Ольга Перепелкина, эксперт в области машинного обучения и нейросетей, преподаватель и автор курса Affective Computing в ВШЭ.
Творчество всегда считалось прерогативой человечества. И если в когнитивных задачах, таких как вычисления и обработка информации, мы уже признали превосходство искусственного интеллекта и активно пользуемся плодами автоматизации, то в таких «человеческих» видах деятельности как живопись, поэзия или композиторство алгоритмы нам уступают. И вообще, разве можно поставить на поток производство шедевров? Однако задачей автоматического создания картин, стихов и музыки ученые занимаются уже несколько десятилетий, и некоторые успехи определенно достигнуты.
Первая музыка, созданная с использованием компьютера, появилась в 1957 году в Bell Laboratories. Это была композиция длиной 17 секунд, которую ее автор Ньюман Гутман назвал The Silver Scale («Серебряная чешуя»):
В том же году The Illiac Suite стала первой партитурой, написанной компьютером. Она был названа в честь компьютера ILLIAC I университета штата Иллинойс в США. Это ранний пример алгоритмической композиции, основанной на вероятностном моделировании (цепях Маркова). В области синтеза звука знаменательным событием стал выпуск синтезатора DX 7 компанией Yamaha в 1983 году, использующего модель синтеза на основе частотной модуляции (FM).
Генерация музыки
Когда мы говорим о создании музыки при помощи компьютера, речь может идти как об ассистивной системе или компьютерной среде, помогающей музыкантам (композиторам, аранжировщикам, продюсерам), так и об автономной системе, нацеленной на создание оригинальной музыки. В обоих типах систем могут участвовать нейросетевые алгоритмы и глубокое обучение.
В обоих типах систем могут участвовать нейросетевые алгоритмы и глубокое обучение.
Мы также можем говорить о разных этапах создания музыки, где искусственный интеллект встраивается в процесс и помогает нам: сочинение, аранжировка, оркестровка и т.д. Когда человек сочиняет музыку, он редко создает новое произведение с нуля. Он повторно использует или адаптирует (сознательно или бессознательно) музыкальные элементы, которые слышал ранее, а также руководствуется принципами и рекомендациями из теории музыки. Так и компьютерный помощник может включаться на различных этапах создания произведения, чтобы инициировать, предлагать или дополнять композитора-человека.
Генерация нот
Традиционным подходом является создание музыки в символической форме. Результатом процесса генерации может быть музыкальная партитура, последовательность событий MIDI (распространенный стандарт цифровой звукозаписи), простая мелодия, последовательность аккордов, текстовое представление или какое-либо другое представление более высокого уровня.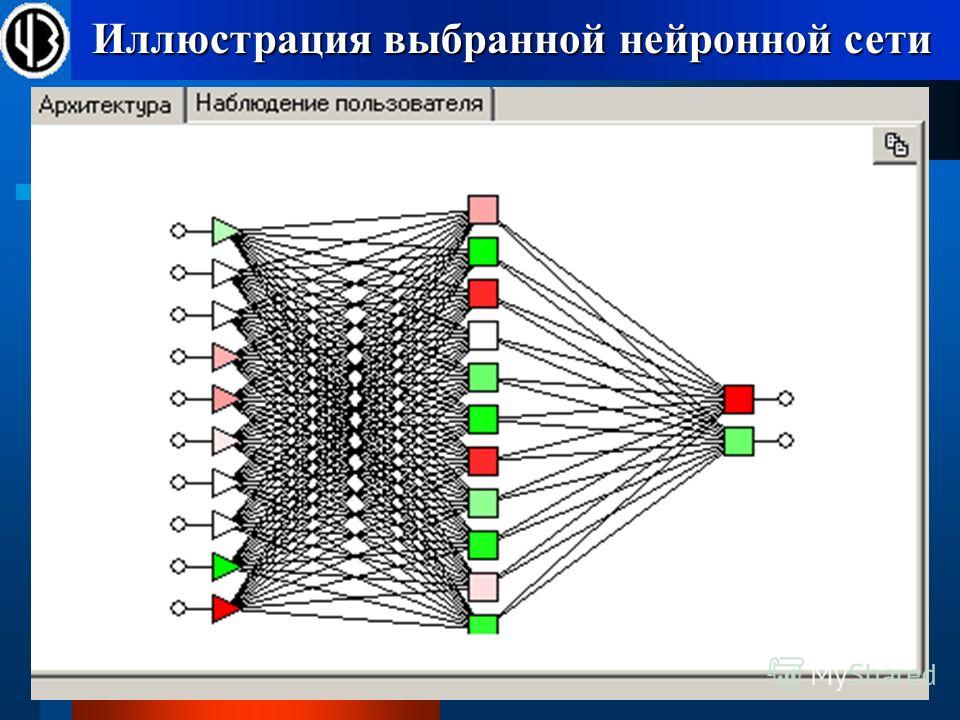 То есть искусственный интеллект создает символическую форму, по которой затем можно сыграть произведение.
То есть искусственный интеллект создает символическую форму, по которой затем можно сыграть произведение.
Иными словами, физический процесс, посредством которого создается звук, упраздняется — вместо создания всего многообразия аудиосигнала, алгоритм выдает «инструкцию». Это резко сокращает объем информации, которую алгоритмы должны производить, что сводит проблему синтезирования к более решаемой и позволяет эффективно использовать простые модели машинного обучения.
Такой подход, например, позволил создать музыку в стиле Баха. Другой пример — нейросеть от OpenAI Musenet, которая появилась в апреле 2019 года. MuseNet может сочинять четырехминутные композиции на десяти инструментах и комбинировать стили «от Моцарта до Beatles». Эта нейросеть была обучена на огромном массиве MIDI-записей.
Генерация аудио
Но символический подход не позволяет создать нюансы человеческого голоса и различные характеристики тембра, динамики и выразительности музыкального произведения. Другой способ — это создавать музыку напрямую в виде аудиосигнала. Сложность этого подхода в том, что последовательность, которую мы в таком случае пытаемся создать — очень длинная. Например, для песни в несколько минут в хорошем студийном качестве это будет десятки миллионов значений.
В апреле 2020 года, компания OpenAI выпустила Jukebox, — нейросеть, которая генерирует музыку в различных жанрах. Она может сгенерировать даже элементарный голос, а также различные музыкальные инструменты. Jukebox создает аудиосигнал напрямую, минуя символьное представление. Такие музыкальные модели имеют гораздо большую емкость и сложность, чем их символьные аналоги, что подразумевает более высокие вычислительные требования для обучения модели.
Как творят нейросети?
Как же именно нейросети создают музыку? Общий принцип заключается в том, что нейросеть «смотрит» на огромное количество примеров и учится генерировать что-то похожее. В основе таких алгоритмов обычно лежат автокодировщики и генеративно-состязательные нейросети (Generative Adversarial Network, GAN).
Автокодировщик — это нейросеть, которая учится представлять сложный и многомерный набор данных в «упрощенном» виде, а затем из этого упрощенного представления снова воссоздать исходные данные. То есть модель генерации музыки на основе автокодировщика сначала сжимает необработанный звук в пространство меньшей размерности, отбрасывая некоторые из несущественных для восприятия битов информации. Затем мы обучаем модель генерировать звук из этого сжатого пространства и повышать качество до исходного звукового пространства.
Генеративно-состязательную нейросеть метафорично можно представить как работу «фальшивомонетчика» и «следователя».
Для обучения модели Jukebox использовал базу данных из 1,2 млн песен (600 тыс. из которых на английском языке), которая включала как сами композиции, так и тексты песен и метаданные — исполнителя, жанр и ключевые слова.
Музыкальный тест Тьюринга
Как понять, что музыкальное произведение, созданное машиной, действительно достойно нашего внимания? Для проверки работы систем искусственного интеллекта был придуман тест Тьюринга. Его идея заключается в том, что человек взаимодействует с компьютерной программой и с другим человеком. Мы задаем вопросы программе и человеку и пытаемся определить, с кем же мы разговариваем. Тест считается пройден программой, если мы не можем отличить программу от человека.
В области генерации музыки иногда используют «музыкальный тест Тьюринга». Так, например, был протестирован алгоритм DeepBach, который генерирует ноты в стиле Баха. Были опрошены более 1,2 тыс. людей (как эксперты, так и обычные люди), которые должны были отличить реального Баха от искусственного. И оказалось, что сделать это очень сложно — люди с трудом могут различать хоралы, сочиненные Бахом, и созданные DeepBach.
В области создания аудио успехи пока не столь впечатляющие. Несмотря на то, что Jukebox представляет собой смелый шаг вперед в плане качества музыки, длины аудио и способности настроиться на исполнителя или определенный жанр, различия между искусственной музыкой и произведениями, созданными людьми, все еще заметны. Так, в мелодиях от Jukebox хоть и есть традиционные аккорды и даже впечатляющие соло, мы не слышим крупные музыкальные структуры, такие как повторяющиеся припевы. Также в искусственных произведениях слышны шумы, связанные со способом работы моделей. Скорость генерации музыки также пока еще невысока — для полного рендеринга одной минуты звука с помощью Jukebox требуется около девяти часов, поэтому их пока нельзя использовать в интерактивных приложениях.
Несмотря на то, что Jukebox представляет собой смелый шаг вперед в плане качества музыки, длины аудио и способности настроиться на исполнителя или определенный жанр, различия между искусственной музыкой и произведениями, созданными людьми, все еще заметны. Так, в мелодиях от Jukebox хоть и есть традиционные аккорды и даже впечатляющие соло, мы не слышим крупные музыкальные структуры, такие как повторяющиеся припевы. Также в искусственных произведениях слышны шумы, связанные со способом работы моделей. Скорость генерации музыки также пока еще невысока — для полного рендеринга одной минуты звука с помощью Jukebox требуется около девяти часов, поэтому их пока нельзя использовать в интерактивных приложениях.
А как же лирика?
Хорошо, с музыкальными композициями разобрались, а как же тексты для песен? Может ли искусственный интеллект сочинять стихи? Да, и эта задача даже проще, чем написание мелодий, хотя и сложностей здесь тоже хватает — алгоритму нужно не только «придумать» осмысленный текст, но и учесть его ритмическую структуру.
В 2016 году разработчики «Яндекса» выпустили альбом «Нейронной обороны». В него вошли 13 песен в стиле «Гражданской обороны», тексты для которых сочинил искусственный интеллект. А годом позже вышел альбом «Neurona» с четырьмя песнями в стиле Nirvana, стихи для которых также были сгенерированы нейросетями.
Сейчас спою
Музыку мы создавать научились, стихи для нее писать — тоже, а как же быть с человеческим голосом? Могут ли нейросети петь вместо нас?
Генерация реалистичного человеческого голоса нужна не только для пения, но и во многих системах — от call-центров до личных голосовых помощников. Еще в 2016 году компания DeepMind выпустила алгоритм WaveNet, который создает очень реалистичный голос по заданному тексту (Text-To-Speech). Технология доступна для двух языков — английского и китайского.
В апреле 2020 года в ByteDance AI Lab (лаборатории компании, создавшей знаменитый TikTok) создали алгоритм ByteSing. Эта система на основе нейросетевых автокодировщиков позволяет генерировать очень реалистичное пение на китайском языке.
Большинство разработчиков современных алгоритмов генерации музыки, стихов и пения отмечают, что их системы являются ассистивными. Они не претендуют на полноценную замену человеческого творчества, а, напротив, призваны помочь человеческой музе. Человек не перестанет творить по мере развития алгоритмов и программ, но будет использовать их в своей деятельности. Очень вероятно, что в будущем великие шедевры будут созданы людьми и искусственным интеллектом совместно.
Искусственный интеллект научился сочинять музыку, совсем как человек
Уроки истории
Эд Ньютон-Рекс по образованию композитор. Он работал над проектом Jukedeck с 2014 года — со временем его команда выросла до 20 человек и смогла привлечь $3,1 миллиона инвестиций.
«Все началось с того, что еще будучи студентом, я задал себе вопрос: а могут ли уже компьютеры сочинять музыку? — рассказал основатель стартапа. — Я решил, что они наверняка должны это уметь, и задумался, какой смысл будет в этом умении.
Каким удивительным образом его можно будет использовать? В итоге я отправился к подруге в Гарвард, где она как раз изучала компьютерные науки. Я посетил что-то вроде вводной лекции в информатику и понял, что в принципе вполне реально научить компьютер писать музыку.
Я начал работать над прототипом — тогда он представлял собой элементарную систему алгоритмического написания музыки. Работа была сложной, и на нее ушло много времени, но в итоге мне удалось сделать довольно неплохой прототип. Я отвез его в инвестиционное подразделение Кембриджского университета, чтобы получить финансирование».
 Каким удивительным образом его можно будет использовать? В итоге я отправился к подруге в Гарвард, где она как раз изучала компьютерные науки. Я посетил что-то вроде вводной лекции в информатику и понял, что в принципе вполне реально научить компьютер писать музыку.
Каким удивительным образом его можно будет использовать? В итоге я отправился к подруге в Гарвард, где она как раз изучала компьютерные науки. Я посетил что-то вроде вводной лекции в информатику и понял, что в принципе вполне реально научить компьютер писать музыку.Фото: Andrii Degeler
ИИ Jukedeck пишет музыку с помощью нейронных сетей — один из многочисленных методов, которые использовались в истории для написания компьютерной музыки. Первые известные эксперименты в этой области проводились еще в 50-х годах XIX века. Первой, кто заговорил о попытках написания машиной музыки, была изобретательница двоичного кода Ада Лавлейс. В 1843 году она написала, что «аналитическая машина Чарльза Бэббиджа может сочинять осмысленные отрывки музыки любой сложности и длины».
В 1843 году она написала, что «аналитическая машина Чарльза Бэббиджа может сочинять осмысленные отрывки музыки любой сложности и длины».
Спустя столетия композитор Лейярен Хиллер и программист Леонард Айзексон написали с помощью искусственного интеллекта сюиту «Иллиак». При ее создании ИИ опирался на правила теории музыки. Для своего времени получившееся произведение звучало довольно неплохо.
В XX веке появился еще один способ написания компьютерной музыки — на этот раз с помощью грамматики. Проще говоря, ИИ пытался проанализировать систему строения музыки и создать по ней собственную мелодию. Среди известных людей, пользовавшихся этим методом, был американский ученый и композитор Дэвид Коуп. Благодаря его идее «рекомбинаторики» появился искусственный интеллект, который мог анализировать существующие музыкальные отрывки и на их основе создавать собственные. Вот так, например, звучит имитация произведения Вивальди:
youtube.com/embed/2kuY3BrmTfQ»/>
Для написания музыки использовалась и так называемая цепь Маркова (система, чье текущее состояние зависит только от предыдущего), ведь ее концепция очень напоминает принцип создания музыки. Так появился алгоритм Continuator, созданный ученым Франсуа Паше, который может продолжать сочинять музыкальное произведение с того места, где остановился живой композитор.
Еще один метод, которым пользовались для создания музыки с помощью ИИ, это эволюционные алгоритмы. Именно их использует проект британских ученых DarwinTunes. Согласно его основному принципу, любой желающий может прослушать различные отрывки музыки и выбрать из них те, что понравились больше всего. Прошедшие такой «естественный отбор» фрагменты эволюционируют, то есть воспроизводятся в новых вариациях.
Вот, например, одна из композиций DarwinTunes:
Несмотря на то, что с помощью этих методов действительно можно сочинять неплохую музыку, у них всегда есть ограничения. Либо они слишком зависят от теории музыки, либо все сводится к индивидуальным предпочтениям человека, который отбирает лучшие образцы созданной музыки.
Либо они слишком зависят от теории музыки, либо все сводится к индивидуальным предпочтениям человека, который отбирает лучшие образцы созданной музыки.
Работа нейронных сетей
По словам Ньютона-Рекса, самой большой технологической трудностью в создании ИИ, который смог бы писать музыку, является то, что не существует «хорошей» или «плохой» музыки. Если взять, к примеру, распознавание изображений с помощью нейронных сетей, то там можно научить алгоритм анализировать, какая картинка правильная, а какая нет.
Но с музыкой так не получится, потому что не существует универсального определения, что такое «хорошая» музыка. Музыканты, работающие над Jukedeck, поставили перед собой цель выработать у алгоритма музыкальный вкус и навыки написания музыки.
«Мы слушаем музыку, оцениваем результат и корректируем сети нужным образом, — рассказал Ньютон-Рекс. — При корректировке мы полагаемся на собственный слух (в конце концов, мы же музыканты!) и на количество скачиваний композиций с нашего сайта («стали ли люди скачивать музыку чаще после внесенных изменений?»).
 Мы используем эти два метода потому что алгоритмическое написание музыки по-прежнему находится на очень раннем этапе развития».
Мы используем эти два метода потому что алгоритмическое написание музыки по-прежнему находится на очень раннем этапе развития».«Стоит отметить, что сама система сильно отличается от того, как работают эволюционные методы, — добавил Ньютон-Рекс. — По эволюционному методу пользователь отбирает лучшие результаты, и система пересоздает их с новыми вариациями — и так до бесконечности. Система ничему не учится. А когда мы используем нейросети, она анализирует данные своего обучения и творит уже на их основе».
Квиз №1. Сможете угадать, какой из этих двух музыкальных фрагментов написан компьютером?
Заменит ли компьютер живых музыкантов?
Несмотря на то, что человечество проводит эксперименты в плане написания музыки с помощью ИИ вот уже более 50 лет, считается, что эта технология еще находится на ранней стадии развития. Однако будущее ее выглядит светлым — по крайней мере, так считают те, кто с ней работают.
«Я очень удивлюсь, если через 10-15 лет большинство музыкальных произведений будет создаваться с помощью искусственного интеллекта», — сказал Ньютон-Рекс.
Это значит, что в будущем композиторам — в частности тем, кто пишет музыку на заказ — возможно, придется искать другую работу.
Сами композиторы пока что не сильно беспокоятся на этот счет. Дмитрий Лившиц, скрипач, инженер звукозаписи и лучший композитор на популярной площадке стоковой музыки считает, что искусственный интеллект и проект Jukedeck смогут достичь мастерства человека еще лишь спустя много лет.
«Электроника звучит более-менее нормально, — сказал он после прослушивания музыки, созданной Jukedeck. — А вот гитары в рок-композициях просто ужас. У такой музыки немного синтетическое звучание, но, думаю, для тех, кто не задумывается, что играет на фоне, сойдет. Рекламные агентства, конечно же, не станут использовать эту музыку, а вот влогеры на YouTube вполне могут».
Лившиц согласен, что когда ИИ сможет создавать действительно хорошую фоновую музыку для видеоблогов и рекламных роликов, стоковым композиторам действительно придется искать новый вид заработка. Однако он не выразил сожаления и заявил, что уже «сотрудничает» с ИИ — а именно пользуется приложением, которое генерирует музыкальные идеи и тем самым помогает композиторам, у которых пропало вдохновение.
Квиз №2. Давайте попробуем еще раз. Какой из этих треков написан компьютером?
Еще один популярный композитор стоковой музыки Олександр Игнатов назвал музыку, создаваемую ИИ, «фастфудным решением» для тех, кому срочно нужна дешевая музыкальная композиция.
«Только образованные люди могут создать произведение искусства, которое будет нести в себе какую-то мысль, — заявил он. — Сомневаюсь, что искусственный интеллект сможет когда-нибудь написать саундтрек к фильму, который бы вызывал мурашки.
 Машина на такое не способна».
Машина на такое не способна».У Ньютон-Рекса другая позиция на этот счет. Он считает, что с помощью творческого ИИ написание музыки станет занятием, доступным более широкой аудитории.
«Сейчас создание музыки — это занятие, доступно только элите, — сказал он. — Чтобы хорошо писать музыку, нужно получить дорогое образование и долго учиться. Музыкальное творчество недоступно большинству людей. ИИ сможет решить эту проблему. С его помощью люди смогут писать музыку, а значит ее станет больше, и она будет более персонализированной».
Однако именно этого и боятся некоторые композиторы.
«Инструменты, позволяющие генерировать музыку, с одной стороны являются отличными помощниками для композиторов, — сказал Владимир Поникаровский, композитор стоковой музыки, который сейчас перешел в индустрию разработки игр. — С другой же, если ими будет пользоваться огромное количество людей, на свет появится тонна некачественного контента, из-за чего может в среднем упасть качество стоковой музыки».
Но Ньютон-Рекс спешит развеять все опасения о том, что ИИ окажет негативный эффект на музыку в целом. По его словам, когда-то все точно так же возмущались по поводу электронных инструментов, и даже было движение против синтезаторов. В итоге благодаря технологическим инновациям в музыке на свет появились целые новые музыкальные жанры — и в будущем может произойти то же самое благодаря ИИ.
А что насчет денег?
Сейчас Jukedeck продает свою музыку по стоимости от $21,99 до $199 (в зависимости от типа лицензии). Частные лица и представители малого бизнеса могут получить неэксклюзивную лицензию бесплатно.
У Jukedeck нет специальной системы для защиты музыки от нелегального копирования, поэтому стартапу приходится полагаться лишь на честность своих клиентов. Хотя, возможно, вскоре ситуация изменится.
«В самом начале мы делали музыку для видеороликов, — рассказал Ньютон-Рекс. — Мы создавали ее для видеоблогеров на YouTube и не монетизировали ее.
 Мы думали так: «Давайте докажем всем, что наша музыка хороша, и ей захотят пользоваться люди». Сейчас же на нашем сайте более полумиллиона композиций. Пока что мы не объявили о следующем шаге, но вообще рассматриваем различные области видеорынка, где могли бы монетизировать свои произведения. Именно этим мы планируем заниматься в ближайшие несколько месяцев».
Мы думали так: «Давайте докажем всем, что наша музыка хороша, и ей захотят пользоваться люди». Сейчас же на нашем сайте более полумиллиона композиций. Пока что мы не объявили о следующем шаге, но вообще рассматриваем различные области видеорынка, где могли бы монетизировать свои произведения. Именно этим мы планируем заниматься в ближайшие несколько месяцев».Представители музыкальной индустрии и крупные игроки технологического рынка тоже обратили внимание на возможность сочинять музыку с помощью ИИ. Например, у Sony есть собственное средство для создания музыки под названием Flow Machines, о котором прошлой осенью много писала пресса. Этот ИИ создал песню под названием Daddy’s Car в стиле The Beatles.
Для Ньютон-Рекса и его проекта Jukedeck появление таких новых игроков с большими ресурсами, означает, что конкуренция на рынке станет гораздо жестче. А для рядового слушателя это значит лишь то, что довольно скоро его ждут совершенно новые музыкальные впечатления.
А для рядового слушателя это значит лишь то, что довольно скоро его ждут совершенно новые музыкальные впечатления.
Источник.
Материалы по теме:
Блокчейн может изменить музыкальную индустрию
Искусственный интеллект научили писать музыку для «активности мозга»
Сотрудники Яндекса записали альбом на стихи, созданные нейросетью
Google научит искусственный интеллект рисовать и сочинять музыку
«Нейронная оборона» и «новый Рембрандт». Как нейросети пишут музыку, картины, киносценарии
Футурологи говорят, что скоро алгоритмы отберут у людей монотонную работу, — программы будут вести бухучет, управлять автомобилями, штамповать детали на заводах. А вот творческим специалистам — художникам, писателям, музыкантам — нечего бояться, по тем же прогнозам. Но сегодня нейросети пишут новые тексты, музыку, картины. Одни проекты подаются как постдокументализм, где автор играет с новыми технологиями в своем проекте, в других замыслах — нейросеть может помогать творцу. А есть картины, сгенерированные алгоритмами, которые уже продаются за деньги. Что думают об этом композиторы, художники и разработчики?
А есть картины, сгенерированные алгоритмами, которые уже продаются за деньги. Что думают об этом композиторы, художники и разработчики?
Курт Кобейн и Егор Летов. Возрожденные нейросетью
«А в глазах у тебя апельсиновый снег, и не будет в помине озлобленных птиц». «Дождик по миру брел живой, за собой вел свои войска».
Одна из цитат принадлежит Егору Летову, лидеру группы «Гражданская оборона». Другая — творение алгоритма, которого предварительно «накормили» песнями панк-рокера, а заодно всей русской поэзией.
Вы, скорее всего, не догадаетесь, где генеративная строчка, а где та, в которую Летов вкладывал чувства. Второй вариант — настоящая «Гражданская оборона».
Давайте еще раз — где Летов, а где алгоритм: «Мне будет сниться, ты можешь сбиться, и как много лет назад, в гости к богу в Ленинград», «Он гремит сапогами, но упал — гололед, и мы — лед под ногами майора».
Спецпроект на тему
В 2016 году Иван Ямщиков и Алексей Тихонов — разработчики «Яндекса» — выпустили альбом «Нейронной обороны» из 13 песен, куда вошла и песня с первой строчкой (про бога и Ленинград). Тогда многие поклонники удивлялись, не могли отличить генеративные тексты от Летова — настолько лирика была выдержана в его стиле.
Тогда многие поклонники удивлялись, не могли отличить генеративные тексты от Летова — настолько лирика была выдержана в его стиле.
«Нейросеть не может выдать осмысленный и связный текст. Мы собирали стихи по одной строчке, — объясняет Иван Ямщиков. — Видим интересную строку — оставляем, ищем ей «пару» и так далее. Видим неинтересную — пропускаем. Но мы ничего не дописывали, все, что есть в текстах «Нейронной обороны», создано нейросетью. Потом мы сочиняли музыку и сами исполняли песни».
Ямщиков и Тихонов выбрали Егора Летова для эксперимента после того, как поняли принцип: алгоритм хорошо стилизует творцов, у которых в текстах много странных и абсурдных образов. Алгоритм выдавал убедительного Даниила Хармса, но сомнительного Пушкина. Егор Летов с его оразами в духе «трогательным ножичком пытать свою плоть» подходил, а еще он просто нравился создателям. «Нейронная оборона» стала успешнее, чем Neurona — альбом Курта Кобейна, который разработчики выпустили спустя год после «возрождения» Летова.
«Нейронную оборону» послушали несколько сотен тысяч человек, а Neurona — около сотни тысяч, — говорит Ямщиков. — Но в первом случае мы собрали русскоязычную аудиторию, а во втором — англоязычную. Можно было лучше продвигать альбом, но это не наша специализация. Мы показываем эти работы на разных IT-конференциях. И делали их для того, чтобы показать людям, что умеют нейросети».
‘ Youtube/Creaited Labs’
Над лирикой Курта Кобейна работали около полугода. «Сначала мы дали нейросети тексты Кобейна и всю английскую поэзию, — вспоминает Ямщиков. — Первые эксперименты показали, что тексты выходят не очень грамотными, дело в том, что в дата-сете были данные с платформ, куда любые желающие могут загрузить свои произведения, — а там есть стихи, написанные не носителями языка. Мы почистили дата-сет и получили симпатичные вещи».
«Наши первые эксперименты в 2016 году удивляли людей, а сейчас примеров того, как алгоритмы пишут музыку, тексты, картины, — много, — рассуждает Иван Ямщиков. — Это вообще интересный общественный процесс. Со второй половины XX века мы живем в мире постмодернизма, когда все уже придумано, сказано, написано, а творцы берут идеи и играют с ними, как с кубиками «Лего». И вот появляется нейросеть и говорит: «Я тоже могу играть в кубики «Лего». Технологии будут развиваться и в этой сфере и пойдут дальше. Представьте, что у вас дома есть не просто картина, написанная нейросетью, а интерактивная картина с сенсорами, датчиками, которая улавливает ваше настроение и в зависимости от него меняет изображение. Или она меняет «картинку» под каждого члена семьи. Вот то будущее, о котором сейчас говорят на научных и IT-конференциях, связанных с машинным обучением».
— Это вообще интересный общественный процесс. Со второй половины XX века мы живем в мире постмодернизма, когда все уже придумано, сказано, написано, а творцы берут идеи и играют с ними, как с кубиками «Лего». И вот появляется нейросеть и говорит: «Я тоже могу играть в кубики «Лего». Технологии будут развиваться и в этой сфере и пойдут дальше. Представьте, что у вас дома есть не просто картина, написанная нейросетью, а интерактивная картина с сенсорами, датчиками, которая улавливает ваше настроение и в зависимости от него меняет изображение. Или она меняет «картинку» под каждого члена семьи. Вот то будущее, о котором сейчас говорят на научных и IT-конференциях, связанных с машинным обучением».
«Башмет сказал: «Да, здорово звучит». О пьесе нейросети
Нейросеть от разработчиков «Яндекса» стала соавтором пьесы, которую исполнил оркестр под руководством Юрия Башмета на прошлогоднем Зимнем фестивале искусств в Сочи.
На эту тему
«Цифровой восход» — так назвали пьесу — длится восемь минут, для ее создания алгоритму «скормили» четыре гигабайта произведений классиков — от Баха и Шнитке до Прокофьева и Шостаковича. Бот сгенерировал мелодии, которые собирал в готовое произведение композитор Кузьма Бодров.
Бот сгенерировал мелодии, которые собирал в готовое произведение композитор Кузьма Бодров.
«Это была идея организаторов фестиваля, — рассказывает он. — Разработчики сами работали с нейросетью, а я получил от них 20–25 аудиодорожек — каждая примерно по три минуты. Большая часть из них — бессвязные. Но я вычленил три-четыре интересных мотива — этого было достаточно — и дал им развитие и форму. Эти мотивы — странные, я бы так не придумал, но в них были какие-то проблески интонаций, которые меня зацепили».
На «сборку» у Бодрова ушло две недели. «Иногда две недели можно только искать идею — с чего начать? Здесь же миллиарды вариантов. А в этом случае мне не нужно было придумывать — основа дана».
На эту тему
Нейросеть создала оригинальные мелодии, но по стилю они напоминали американский минимализм. «Там паттерн много-много раз повторяется, — продолжает Бодров. — Я могу сказать, что получилось хорошо. Музыкантам понравилось, они говорили: «Клево», «Интересно». Но главная оценка — это слова Юрия Абрамовича Башмета. Он послушал и сказал: «Да, здорово звучит. Симпатичная вещь получилась».
Он послушал и сказал: «Да, здорово звучит. Симпатичная вещь получилась».
Кузьма Бодров раньше не использовал алгоритмы в создании композиций. А вообще музыканты регулярно экспериментируют с нейросетями. Пару лет назад победители конкурса классической музыки в Германии использовали бота для создания мелодии.
Новый Рембрандт…
В апреле 2016 года команда разработчиков, спонсируемая Microsoft и голландским банком ING, показала обществу проект «Следующий Рембрандт» под лозунгом «Через 347 лет после смерти Рембрандта представлена его следующая картина».
С помощью нейросетей разработчики выявили параметры, которые делали его уникальным творцом, начиная от выбора темы работы до точных пропорций типичных рембрандтовских полотен. Получили преобладающую модель, которая представляла из себя «мужчину 30–40 лет в черном платье с белым воротником, лицо повернуто вправо». Этот комплекс параметров использовали для создания оригинального портрета, выполненного в стиле художника.
… и самая дорогая генеративная картина
Другой случай взволновал профессиональных художников. В 2017 году картина, написанная нейросетью, была продана за $432 тыс. на аукционе Christie’s в Нью-Йорке. Эксперты изначально оценивали «Портрет Эдмона Белами» в $7 тыс.
«Портрет Эдмонда Белами»
© Пресс-служба аукционного дома Christie’s«Почему это кажется почти невероятным? Аукционные продажи опираются на такие вещи, как авторство, уникальность. Автор — такой демиург, работами которого хотят обладать коллекционеры, — говорит Александр Евангели, арт-критик, преподаватель в школе им. Родченко. — И когда работа, написанная алгоритмом, оказывается в рамке, за нее идет борьба, и она продается за такую сумму, — эта основа оказывается подорвана. Рыночный механизм сохраняется, а смысл — нет».
Впрочем, это единичный случай, подавляющее большинство картин, созданных нейросетью, ничего не стоят. И цена — не критерий в сфере искусства, добавляет Евангели: «Работы дадаистов очень низко оцениваются рынком — можно купить картину за $10 тыс. , что совсем не соответствует вкладу этих творцов в культуру. Но профессионалы понимают — это искусство».
, что совсем не соответствует вкладу этих творцов в культуру. Но профессионалы понимают — это искусство».
Алгоритмы породили в арт-среде много вопросов. «Чем будет искусство через 10–15 лет — трудно сказать, но оно потеряет сегодняшние границы, — говорит Евангели. — Рынок вокруг генеративного искусства к тому времени сформируется, почему нет? Сегодня продаются копии картин –— вы можете купить совсем недорогую картину и украсить дом. И вы можете купить картину, сделанную нейросетью, пусть она ничего не стоит сверх материалов, и повесить дома. Просто у людей есть потребность в украшении окружающей среды, но это не имеет отношения к искусству, речь идет о дизайне. Искусство, во-первых, останется как человеческая практика. Ведь живописцы любят писать картины, как люди любят играть друг с другом в шахматы, хотя алгоритмы уже давно играют лучше. А во-вторых, современное искусство будет комбинировать традиционные подходы и технологии».
«Картины, написанные нейросетью, — это неинтересно»
Елена Никоноле — медиахудожник, выпускница школы им. Родченко. У нее несколько проектов, связанных с нейросетями.
Родченко. У нее несколько проектов, связанных с нейросетями.
Первый эксперимент — проект Deus X mchn: нейросеть, которая обучалась на сакральных текстах из разных мировых религий — от Ветхого завета до Корана, анализировала их параметры и в итоге написала свой текст. Это сгенерированный псевдорелигиозный текст, в котором появились несуществующие слова.
«Вражебесное», «человеколетль», — приводит пример Елена. На втором этапе проекта Никоноле вместе со своей командой получала доступ к камерам с динамиками и прочим девайсам, имеющим выход в интернет и расположенным в общественных местах разных городов мира. «Огромная часть устройств по всему миру не защищены паролем», — говорит художница. Через устройства транслировался этот псевдосакральный текст.
У художницы есть и другой эксперимент.
На эту тему
«Я обучила нейросеть на звуках пения соловья — а у них довольно сложная структура песни. Алгоритм анализировал и выделял паттерны в звуках и генерировал свои — сначала это было соловьиное пение с узнаваемыми технологическими «нотами», но по мере того, как нейросеть обучалась, она выдавала все более похожий результат. Я включала эти звуки птицам, они реагировали и начинали «разговаривать» с искусственным интеллектом. Мне было важно выразить метафору — общение искусственного разума с природой. Второй этап — алгоритм-переводчик, который сможет перевести на человеческий язык пение птиц».
Я включала эти звуки птицам, они реагировали и начинали «разговаривать» с искусственным интеллектом. Мне было важно выразить метафору — общение искусственного разума с природой. Второй этап — алгоритм-переводчик, который сможет перевести на человеческий язык пение птиц».
Никоноле считает, что эксперименты с нейросетями в искусстве будут продолжаться. «Но картины, написанные нейросетью, — это базовый уровень, это неинтересно, — говорит она. — Интереснее комбинировать и выражать смыслы через использование технологий».
Гарри Поттер и странная научная фантастика
Алогориты не умеют создавать истории, ведь они, в отличие от людей-творцов, не понимают смысла того, что делают. Этот факт иллюстрирует короткометражка по сценерию нейросети.
Sunspring — семиминутный фильм «о будущем, в котором люди столкнулись с массовой безработицей и, чтобы выжить, вынуждены продавать свою кровь». Идею, сценарий и диалоги написала программа, которой скормили много научной фантастики — от «Звездных войн» до «Терминатора». Создатели не вмешивались в «авторский замысел», потому что уловить смысл в диалогах героев почти невозможно.
Создатели не вмешивались в «авторский замысел», потому что уловить смысл в диалогах героев почти невозможно.
Еще авторы на чикагской студии Botnik использовали нейросеть для создания рассказа о Гарри Поттере. Алгоритму «скормили» романы Джоан Роулинг и попросили его написать новый. В трехстраничном рассказе «Гарри Поттер и портрет того, что выглядит как огромная куча пепла» друг Гарри — Рон — превращается в паука и пытается съесть родителей Гермионы.
Есть и относительно успешный кейс по применению нейросетей в создании историй. Три года назад короткий роман «День, когда компьютер напишет роман», написанный алгоритмом японцев, вышел в финал конкурса авторов. Создатели не только «покормили» нейросеть дата-сетом, но и прописали героев, события. Это был не единственный претендент на победу среди алгоритмов, десяток других нейророманов не вошел в шорт-лист.
Хотя арт-деятели уверены, что творения алгоритмов — это не искусство, в рамки современного искусства вписываются сами эксперименты. Тот же «Портрет Эдмона Белами» ставит вопрос о ценности авторства и рушит нормы рынка, появившегося раньше, чем ученые начали предсказывать появление искусственного разума.
Тот же «Портрет Эдмона Белами» ставит вопрос о ценности авторства и рушит нормы рынка, появившегося раньше, чем ученые начали предсказывать появление искусственного разума.
Анастасия Степанова, Габриэла Чалабова
История падения музыки от Адриана Леверкюна до Дэвида Коупа
Вчера мы в первом приближении рассмотрели экспансию искусственного интеллекта на традиционную площадку творчества — написанное слово. Какими бы впечатляющими ни были достижения компании Narrative Science и её движка Quill, говорить о замене писательского труда в обозримом будущем не приходится. Максимум, на что способен «компьютерный журналист», — это написать удобоваримым языком отчёт с элементами статистического анализа. Даже о намёке на самое примитивное литературное творчество можно не мечтать: AI никогда не заменит не то что Шекспира, но даже Паоло Коэльо (хотя Дэна Брауна лет через десять наверняка скопирует).
Счастье человека (и несчастье Голема) в том, что магия художественного образа обитает по ту сторону информации. Вернее — вообще никакого отношения к информации не имеет. Не случайно даже на заре семиотики (в частности уже в «Открытом произведении» Эко) было понимание того, что в чисто информативном плане художественный образ на несколько порядков превосходит любой научный концепт. Что же говорить о психологических и эмоциональных коннотациях, присутствующих в любом даже самом слабеньком художественном образе и напрочь отсутствующих в самых сложных информационных объектах (то есть научных понятиях)?
Вернее — вообще никакого отношения к информации не имеет. Не случайно даже на заре семиотики (в частности уже в «Открытом произведении» Эко) было понимание того, что в чисто информативном плане художественный образ на несколько порядков превосходит любой научный концепт. Что же говорить о психологических и эмоциональных коннотациях, присутствующих в любом даже самом слабеньком художественном образе и напрочь отсутствующих в самых сложных информационных объектах (то есть научных понятиях)?
О неспособности искусственного интеллекта справиться с художественным текстом (и порождаемой этим текстом образностью) можно говорить очень долго, однако для наших целей хватит понимания самого главного: художественный образ априорно не дискретен и, как следствие, не выводится из информации. Сколько бы Quill ни обрабатывал данных из «Твиттера», биржевой аналитики, политических событий и статистики по недвижимости, AI-движок никогда не сможет вывести из данной в его ощущения эмпирики на подлинный художественный уровень. То есть заменить чисто информационных журналистов у компьютеров получится уже в ближайшее время, заменить же колумнистов, тем более настоящих писателей, не удастся никогда.
То есть заменить чисто информационных журналистов у компьютеров получится уже в ближайшее время, заменить же колумнистов, тем более настоящих писателей, не удастся никогда.
Сегодня, однако, мы поговорим о другом — чрезвычайно тревожном, на мой взгляд, — аспекте экспансии искусственного интеллекта на территории творчества человека. О музыке. Моя тревога объясняется тем, что добиться иллюзии полноценной музыкальной композиции с помощью компьютерных технологий значительно проще, чем имитировать художественный текст. Причина — в силе и одновременно слабости музыки как искусства. Причина — в том, что делает музыку максимально приближенной к Богу (музыка — это квинтэссенция эстетики, высшее искусство) — и в то же время уязвимой для профанации.
Музыка — это эмоция в дистиллированном виде, которая к тому же ещё и оторвана от прямых смыслов. Музыка, подобно поэзии (в большей мере) и прозе (в меньшей), способна породить художественную образность, которая на порядок превосходит по информативности научные понятия, однако все эти образы, порождённые музыкой, будут исключительно опосредованы. То есть будут рождаться в голове слушателя, а не из комбинации музыкальных нот. Ноты создают тональность и настроение, которые, в свою очередь, порождают образы и несут информацию. Сама же музыка — вне информации, вне прямых смыслов.
То есть будут рождаться в голове слушателя, а не из комбинации музыкальных нот. Ноты создают тональность и настроение, которые, в свою очередь, порождают образы и несут информацию. Сама же музыка — вне информации, вне прямых смыслов.
Это качество музыки возносит её над остальными искусствами; оно же, боюсь, её и погубит.
Дэвид Коуп (David Cope) родился в Калифорнии в 1941 году, влюбился в музыку в раннем детстве, получил блестящее образование и обещал затмить самого Гершвина. Юный композитор создал несколько ярких произведений малого жанра, получил восторженные отзывы критики и вместе с ними заказ на создание — ни много ни мало — полномасштабной оперы! В 1980 году Дэвид Коуп сел писать произведение, которое должно было вознести его до небес, и… сломался!
Коуп пыхтел почти полгода, но не сумел создать даже увертюру. Дальше пыхтеть возможности не было, потому что несостоявшийся композитор имел жену и четверых детей, которых нужно было чем-то кормить. И тогда Коуп вспомнил об Адриане Леверкюне и продал душу дьяволу. В отличие от трагического героя Томаса Манна, Дэвиду Коупу не пришлось общаться с нечистой силой: достаточно было подружиться с компьютером!
И тогда Коуп вспомнил об Адриане Леверкюне и продал душу дьяволу. В отличие от трагического героя Томаса Манна, Дэвиду Коупу не пришлось общаться с нечистой силой: достаточно было подружиться с компьютером!
Одной дружбы, как вы понимаете, было мало, требовался ещё некий хитрый изъян в душе, который позволил бы направить энергию в нужное русло. Изъян Дэвида Коупа отлился в сентенцию, за которой скрываются все его убеждения: «Вопрос не стоит — есть ли душа у композитора. Вопрос — есть ли душа у всех нас!»
Для себя Дэвид Коуп решил однозначно (после затяжных вигилий над оперой): души нет! Ни в композиторах, ни в слушателях, ни вообще у остальных людей. А что же есть? Есть технологии!
Поверив в Голема (исполина без души), Дэвид Коуп очень легко нашёл «эликсир счастья». (Хотел написать «формулу успеха», но вовремя одумался: успех в «творчестве» Коупа, слава тебе, господи, не ночевал ни разу!) Как работали великие композиторы, если не имели души, а музыка не была отражением небесных сфер? Великие композиторы, рассудил Дэвид Коуп, внимательно слушали! Слушали других композиторов — своих современников и предшественников. В результате их мозг «рекомбинировал» услышанные мелодии и музыкальные фразы. Рекомбинировал на собственный — оригинальный — лад.
В результате их мозг «рекомбинировал» услышанные мелодии и музыкальные фразы. Рекомбинировал на собственный — оригинальный — лад.
От этой идеи рукой подать до компьютерных технологий, способных «писать музыку». Из великого музыкального наследия человечества создаётся база данных на основе как можно большего количества элементарных музыкальных фраз — мотивы, мелодии, яркие аккорды, переходы и т. п. После чего компьютеру даётся задание: перетасовать эти элементарные фразы таким образом, чтобы получилось нечто оригинальное!
Первой жертвой Дэвида Коупа стал Иоганн Себастьян Бах. В 1983 году новый доктор Фаустус разложил творчество великого немца на составляющие, затем перекомбинировал их и «создал» новый хорал. «В стиле Баха». Из этих экспериментов родилась Emmy — первый движок искусственного компьютерного интеллекта, приспособленный к написанию музыки.
Новые мощные процессоры открыли перед Дэвидом Коупом головокружительные перспективы: однажды утром он запустил Emmy и отправился завтракать, а по возвращении с восторгом обнаружил, что его Мефистофель наштамповал 5 тысяч новых — «оригинальных» — хоралов Баха! В 1993 году Дэвид Коуп выпустил свою первую пластинку, названную Bach by Design (Centaur Records, CRC 2184).
В 1997 свет увидела «Классическая музыка, написанная компьютером» («Classical Music Composed by Computer»), следом, чуть позже, — «Виртуальный Моцарт» («Virtual Mozart». 1997), «Виртуальный Бах» («Virtual Bach», 2003).
Затем наступила пауза. Дело в том, что музыкальные критики встретили «творчество» Дэвида Коупа не то что в штыки, а просто с ненавистью. Каждая новая пластинка воспринималась как личное оскорбление любым человеком, который был связан с музыкой или просто любил её. Рецензии на опусы получались зубодробительными, однако все они сводились к одному лейтмотиву: «В этой музыке нет души».
Дэвид Коуп негодовал, насмехался, предлагал пари, настаивая на невозможности отличить работу живого композитора от продукции его Emmy. Стену непонимания и отторжения пробить не удавалось. Сначала Коуп недоумевал, а потом его в очередной раз осенило: чем его Emmy хуже великих музыкальных классиков? Тем, что они уже умерли, а Emmy пока жива! Вот если её умертвить, то творчество её получит необходимый импульс для признания. (Вот и начался «Доктор Фаустус» по полной программе!)
(Вот и начался «Доктор Фаустус» по полной программе!)
В 2003 году Дэвид Коуп «убивает» свою Emmy и шесть лет ничего не «пишет». Все это время профессор музыки в Калифорнийском университете (мирское прикрытие Коупа!) лепит нового Голема — «дочку» Emmy, Emily Howell, использующую гораздо более солидные компьютерные мощности (Emmy питалась соками допотопного Power Mac 7500).
В память вложено творчество 36 композиторов («От Палестрины до самого Дэвида Коупа»), из которого неоголемша лепит оригинальные музыкальные фразы. Сам доктор Фаустус сидит рядом и помогает компьютеру делать «правильный выбор»: бракует мелодии и аккорды, выбирает из десятка ходов такой, который, на его личный взгляд, больше понравится публике.
В 2009 Коупа / Emily Howell прорвало: выходит пластинка From Darkness, Light (Emily Howell), затем подряд три симфонии (№4, №5 и №9), два струнных квартета, концерт для скрипки, концерт для виолончели, концерт для пианино. Доктор Фаустус внутренне уже созрел, чтобы закричать «Verweile doch, du bist so schön!», однако музыкальное сообщество, как и раньше, не даёт расслабиться: что бы ни выдавал на-гора «композитор», оплодотворённый искусственным интеллектом, он тут же подвергается беспощадной критике. С прежним мотивом: нет души!
С прежним мотивом: нет души!
Я внимательно прослушал образцы «творчества» Дэвида Коупа / Emily Howell (на YouTube самим демиургом выложено 371 видео) и вот что подумал: если бы в 1993 году Коуп никому не сказал, что его музыку пишет не он сам, а компьютер, никто бы никогда не догадался! И это — самое страшное.
Безусловно, любой искушённый в музыке человек мгновенно усмотрит нескончаемую «цитацию», однако это обстоятельство можно смело выдать за расхожий приём постмодернизма без ущерба для эстетического эффекта, который от заимствований (или — отсутствия оных) никак не зависит. Эстетический эффект либо есть, либо его нет. На мой взгляд, во многих «творениях» музыкального доктора Фаустуса этот эффект однозначно присутствует, хотя «души» там нет. Причина — та же, что помянул вначале: в отличие от художественного текста, образность музыки рождается не в самой музыке, а в голове слушателя (ноты лишь стимулируют появление этой образности, подобно психотропным веществам).
Самое ужасное, что к творчеству Дэвида Коупа в последнее время с образцовым напором подбираются дельцы попсовых развлечений. В отличие от сообщества любителей классики, бритнёвая спирсня совершенно лишена щепетильности и с лёгкостью обменяет душу (которой все равно у неё нет, как нет у Голема) на звонкую монету. По этой причине, если только Emily Howell начнёт штамповать вместо импровизаций в стиле Баха хиты для MTV, успех затмит самые смелые ожидания.
Вопрос: учитывая всё сказанное, можно ли ожидать, что через 10 лет вся рок-музыка будет создаваться компьютерами целиком — от первой ноты до последнего скэта?
Нейросети и кого в них ловят
Автор: Георгий Куриленко, гик («увлечённый высокими технологиями человек»)
Нейросети – это одна из форм организации искусственного интеллекта (ИИ). Мы можем у него многому научиться, потому что он выходит из привычной человеку плоскости. Его мышление не ограничено рамками наших стереотипов. ИИ использует невообразимые для нас алгоритмы и за счёт этого побеждает: в шахматы, в го, в StarCraft, в диагностику рака. И скоро «уделают» нас даже в музыке и живописи!
ИИ использует невообразимые для нас алгоритмы и за счёт этого побеждает: в шахматы, в го, в StarCraft, в диагностику рака. И скоро «уделают» нас даже в музыке и живописи!
Дотошные нейрофизиологи подсчитали, что в человеческом мозге 86 миллиардов нейронов. Если провести аналогию с компьютером, то получится 86 миллиардов бит информации. Но скажу сразу: такая аналогия ошибочна. Это всё равно что представить себе сравнение мозга, на ранних этапах развития техники, с телеграфом. История про 86 миллиардов «транзисторов» настолько же отражает действительность, как и сравнение с примитивным электрическим устройством. Просто в силу умственных способностей нам так проще.
Также подсчитано, что мощность мозга составляет приблизительно 25 Ватт – это как четыре работающих зарядки для современного мобильного телефона.
Мозг занимает 1,5-2% массы тела. Даже у муравьёв соотношение процента мозга к остальной массе тела больше! И при этом наш мозг потребляет 25% энергии всего организма. По сути, если вы будете целый день просто лежать целый день на диване, то уже потратите четверть своей энергии на одну только работу вашего мозга, я уже не говорю про пищеварение, кровообращение, дыхание и прочее. Мозг действительно очень энергозатратный. Наш организм скупой, не хочет тратить ресурс, ему проще накопить жирок, быть более энергоэффективным. Поэтому любой орган, который потребляет четверть ресурса всего организма – это нонсенс для естественной системы.
По сути, если вы будете целый день просто лежать целый день на диване, то уже потратите четверть своей энергии на одну только работу вашего мозга, я уже не говорю про пищеварение, кровообращение, дыхание и прочее. Мозг действительно очень энергозатратный. Наш организм скупой, не хочет тратить ресурс, ему проще накопить жирок, быть более энергоэффективным. Поэтому любой орган, который потребляет четверть ресурса всего организма – это нонсенс для естественной системы.
Объём памяти мозга может достигать 1016 бит – это более 1250 терабайт. И тут тоже есть разные точки зрения, что терабайт значительно больше, ведь цифра была получена исключительно анализом нейронов. А помимо них существуют ещё и синапсы, то есть связи нейронов между собой, и отдельные белки в мозге. Это лишь предположение, мы не можем посчитать объём мозга, просто как флешки.
Средний размер мозга уменьшился, как говорят антропологи, за последние 40 тысяч лет на 150 грамм. Вот хороший вопрос, почему мы тупеем https://un-sci.com/ru/2020/01/13/idiotokratiya-skolko-let-ostalos-do-pobedy-gluposti/ ? Если всю историю мы наращивали мозги, то тут не только притормозили, а ещё и сдали назад. Но ведь реально же не надо ничего знать, для того чтобы делать посты в Инстаграме! Не надо быть экспертом в какой-то области, достаточно просто выполнять свою работу на среднем уровне. Мы из эры Гутенберга движемся в эру Цукерберга, как сказал кто-то. Мы тупеем как индивидуалы, но умнеем как вид, потому что можем наращивать объёмы информации, которая у нас имеется.
Чего мы не знаем о мозге? Ответ прост: ничего. Все наши познания крайне точечны. Мы примерно представляем, куда нужно ударить током человеку в мозг, чтобы он почувствовал радость, испытал оргазм либо чтобы увидел какие-то галлюцинации. Но как это глобально взаимосвязано, мы не понимаем.
В компьютере одна конкретная единица выполняет одну свойственную ей функцию. Это либо память, либо процессор (то есть, вычислительная способность), либо это программа. У нас всё это вместе: каждый нейрон одновременно выполняет и функцию запоминания, и функцию мышления, при этом он может связываться с другими нейронами по собственной воле. У нас до 25 лет прорастают сквозь мозг новые нейронные связи.
Лет шесть назад произошёл любопытнейший случай: у человека начала неметь нога, он обратился к врачам, те обследовали его в томографе – и МРТ показало, что у этого мужчины 90% мозга отсутствует! Есть только кора, а всё, что внутри, заполнено жидкостью. При этом его IQ был 75. У умственно отсталого IQ 70, то есть всё, что выше 70-ти, считается нормальным человеком, он абсолютно обладает всеми теми же правами, что и мы с вами, может водить машину, вступать в брак, заключать сделки. У того мужчины даже было двое детей! То есть, с эволюционной точки зрения он выполнил своё предназначение. Имя этого человека не разглашается, ему было 44 года, и всю свою жизнь он жил с гидроэнцефалитом – так называется это заболевание. Медики выяснили, что по мере того, как его мозг разрушался под действием этой жидкости, другие отделы мозга перенимали на себя функции. Это можно посмотреть также на примерах жертв катастроф, неудавшихся самоубийц и перенесшими инсульт. Этот процесс называется нейропластичность. У мужчины одна кора переняла на себя все иные функции. При этом он вполне успешно работал чиновником!
Как устроено наше мышление? Есть клетки мозга нейроны, а связи между ними это синапсы. Когда сигнал поступает к нейрону, он либо достаточно сильный, чтобы пройти дальше, либо недостаточно сильный, и тогда он тормозится. И в зависимости от того, как мы проходим дальше, и происходит вычисление. Естественно, всё это происходит в трёхмерном пространстве. Допустим, нам надо отличить апельсин от банана. Мозг оценивает цвет, форму, запах, фактуру поверхности, и «взвешивает» информацию, передаваемую каждым нейроном. Как заставить ИИ отличать апельсин от банана и собачек от котиков? Мы берём так называемый «случайный шум», даём специальной нейросети – Генератору, — которая берёт шум, находит знакомые очертания и на основании этих очертаний достраивает изображение котика. Дальше берём выборку собачек из интернета и берём нейросеть под называнием Дискриминатор, которая должна оценивать, похож ли этот зверёк на собачку. Если похож, то всё нормально, отправляем пользователю. Если не похож, то отправляем на вторичную переработку. Так работают современные генеративно-дискредитивные системы. Это похоже на соревнование фальшивомонетчика и полицейского. Полицейский постоянно старается подделать купюру, а полицейский смотрит на оригинал и ищет мелкие отличия. То есть и Генератор, и Дискриминатор постоянно учатся находить всё более и более тонкие отличие. Если вы не собачка а котик, значит, всё отправляется на второй круг.
Но до сих пор – ура! — то, что для нас является элементарным, для ИИ является непреодолимой задачей. Курьёзны примеры, когда ИИ не мог различить на фото крупного плана, где чихуахуа, а где кекс с черникой, или собачек, которые свернулись калачиком, от реальных калачиков. Или шпицев от печенек, или щенков от жареной курочки. Нам не нужно детально разбирать изображения, чтобы понять, что это. А машины анализируют изображения попиксельно, определяя связи между этими пикселями. Причём желательно, чтобы они были чересчур контрастными, чтобы выделить все неровности и шероховатости. С «белым шумом» панда будет уже восприниматься ИИ как гиббон.
Мы до сих пор во многом превосходим ИИ, но он уже наступает нам на пятки. Если вы думаете, что делаете музыку лучше, то это ненадолго. Музыка, полностью написанная ИИ, уже существует (концерт для нескольких музыкальных инструментов), ничем не уступая Мусоргскому или Рахманинову. Не так давно официально был заключен контракт между звукозаписывающим лейблом и производителем программного обеспечения, чтобы мы могли покупать диски, написанные нейронными сетями. Коммерческая индустрия с большей охотой будет покупать дешёвую музыку, написанную нейросетями – просто вам для заметки.
Картины, в правом углу которых вместо имени художника подписан математический алгоритм, который генерировал эту картину, уже продавались на аукционах за тысячи долларов. Но успехи ИИ в живописи характеризуются не только абстрактным искусством и приложениями для смартфонов, которые могут «переводить» вас или ваших животных в картины, якобы написанные известными художниками (вам достаточно выбрать стиль, и любое изображение будет в него преобразовано), но и головокружительными способностями восстанавливать, воссоздавать утерянные шедевры! Известен случай с картиной Пикассо под названием «Старый гитарист», которую просканировали при помощи мощных рентгеновских сканеров, и под ней была обнаружена другая картина (холсты были очень дорогими, и художник рисовал поверх своих старых работ). «Нижнюю» картину отсканировали при помощи нейросети, а потом использовали ещё одну картину Пикассо для того, чтобы взять оттуда авторский стиль, и таким образом нейросеть сама разукрасила чёрно-белое после сканирования «нижнее» изображение обнажённой женщины. То есть, мы фактически восстановили потерянный шедевр Пикассо, спустя очень много лет после написания. Кстати, под Моной Лизой тоже есть её устаревшие версии!
ИИ может даже уже читать и визуализировать наши мысли. Людей поместили в томограф и сканировали их активность мозга, когда им показывали разные картинки. Нейросеть восстанавливала изображения по волнам мозга. Бокал пива, к слову, угадывается лучше всего! Эта же технология может помочь нам визуализировать сны. Если у вас перед глазами текст, то для ИИ не проблема будет его прочитать по мыслям. Нейросеть уже без проблем распознаёт цифры, которые «слышит» по волнам мозга и безошибочно реагирует на счёт от 1 до 10.
Надо сказать, что мы сами всячески приближаем тот день, когда ИИ станет в разы обученнее нас. Например, мы учим его, когда нам для входа на сайт предлагают капчу – выбрать везде где машины, или где пешеходные переходы. Так мы учим ИИ, который отвечает за беспилотные автомобили. Если верить предсказаниям Рея Курцвела, коммерческого директора Google, компаниям в Америке запретят производить автомобили без автопилота. А предсказания этого человека обычно сбываются с точностью до года.
Впервые в истории летом 2019 года нейросеть создала вакцину от гриппа (уже ведутся её испытания на людях!). Да ещё и сделала таким образом, что вакцина а) усиливает иммунитет и б) способна генерировать новые соединения белков, которые ранее были неизвестны. Дело в том, что грипп гораздо быстрее может мутировать, чем мы: нам, чтобы мутировать, нужно перенести свои гены, то есть размножиться, дать потомство. А у вирусов и бактерий есть такой инструмент, как бесконтактный перенос генов. То есть если бактерия попадает во враждебную среду, она может обменяться геномом с другими бактериями и перенять у них эффективные наработки – поэтому вирусы очень быстро мутируют, приспосабливаются к условиям. Именно поэтому нельзя пользоваться антибиотиками без назначения врача, либо не пропивать до конца курс: вы убьёте только часть бактерий в своём организме, а остальная, наоборот, получит резистентность к этому виду антибиотика. Изобретатель пенициллина Флеминг даже сам предсказывал, что рано или поздно его панацея потеряет свои свойства. И сейчас уже никто не лечится пенициллином – он был эффективен в 40-50-е годы, и с тех пор все бактерии приобрели к нему иммунитет.
Другая нейросеть создала лекарство от мышечного фиброза за 21 день. Так называемые Big Pharma, то есть компании, которые занимаются производством лекарств, тратят на них миллионы долларов и годы тестирования – поэтому лекарства такие дорогие. А тут было потрачено всего 150 тысяч долларов. По меркам фармацевтической промышленности, это копейки. Так что в 2020 году можно ждать новые кейсы, когда ИИ обеспечивает нас ещё теперь и лекарствами.
Вспомним хронологию, как развивались нейросети. В ХХ веке возникли алгоритмы и наука кибернетика. В 70-90-е годы настала так называемая «зима искусственного интеллекта» — застой, ничего не происходило, потому что не было возможности обучать нейронные сети. Это сейчас у нас есть очень много цифровых изображений – а тогда, чтобы оцифровать фото, нужно было потратить очень много усилий, причём даже если был бы некий сканер. Застой был преодолён окончательно с изобретением новых алгоритмов, основанных на большой базе данных – то, что называется во всём мире Big Data, и к 2010 году в этом деле произошёл ощутимый прорыв, нейросети стали делать очень зрелищный результат. Каждый раз, когда вы лайкаете чьё-то фото, или с кем-то переписываетесь, или разговариваете по скайпу – интернет всё это запоминает. Это не выкладывается в открытый доступ, это не персонализировано (что конкретный человек говорил то-то и то-то) – просто это всё складывается в одну общую базу данных, которая впоследствии служит для обучения ИИ. Мы когда пользуемся этими всеми сервисами бесплатно, мы подписываем пользовательское соглашение, кликаем «принять». Если бы вы читали это соглашение, для вас не было бы новостью то, что я сейчас рассказываю. А так мы даже зачастую не знаем, что наша личная информация и все наши бизнес-тайны используются скопом для обучения некоего ИИ https://un-sci.com/ru/2020/01/03/bog-3-0-ili-pobeda-nad-smertyu-strashnee-yadernoj-bomby/.
С 2016 года начался бум коммерческого применения нейронных сетей. Сейчас есть люди, которые на этом неплохо зарабатывают, а до того это всё было просто интересным развлечением.
Моя любимая книга — «Мечтают ли андроиды об электроовцах?» Артура Кларка. По ней был снят фильм «Бегущий по лезвию бритвы» Ридли Скотта 1982 года (уже вышло его продолжение, в котором действие происходит в 2049 году). Книга об отношениях человека с ИИ: способна ли мыслящая машина чувствовать, а не просто имитировать свои чувства. И вопрос в фильме стоит: а способен ли чувствовать ты? Или сам тоже просто имитируешь чувства?
Все помнят 1997 год, когда человек впервые проиграл, как тогда шутили, калькулятору. На самом деле, это был суперкомпьютер компании IBM под названием Deep Blue и поединок с ним Гарри Каспарова. До тех пор никто не верил, что человек не может проиграть машине в шахматы. Может, он хуже считает, с умножением-делением справляется похуже. Но в шахматах нельзя просто перебирать ходы, там их слишком много! И железкина грубая сила, brutal force, не подходит для того, чтобы играть в шахматы. Но в 97-м году компания IBM взяла и разрушила все эти стереотипы, и теперь уже любое соревнование человека и компьютера в настольной игре расценивают как соревнование между боксёром и младенцем (разумеется, в роли «боксёра» нейросеть). Человек никогда уже не достигнет того уровня, на котором играют компьютеры. Каспаров не соглашался с этим проигрышем, утверждал, что были люди, которые специально обучались на его играх, исследовали их и запрограммировали компьютер – короче, много придумывал отмазок для того, чтобы не признать результат. Но факт остаётся фактом: люди никогда с тех пор в шахматы не выигрывали. «Мне всегда было интересно, как это будет, когда высшие существа приземлятся на Землю и покажут нам, как они играют в шахматы. Теперь я знаю», — сказал об этом скандинавский гроссмейстер Петер Хайне Нильсен.
2016 год ознаменовался победой нейросети AlphaGo над корейским игроком в го Ли Седоля, профессионала 9-го дана, то есть высшего ранга. До того люди были уверены, что ладно шахматы, но в го компьютер точно не сможет обыграть человека, потому что эта древняя китайская игра требует много фантазии, интуиции, абстрактного мышления и тому подобное. Это не игра, а искусство и философия. Школы го уже несколько сотен лет непрерывно подготавливают гроссмейстеров, изучают все ходы, которые были сделаны за всю историю игры; нестандартные решения приобретают даже названия: «Лестница в небо», «Выход дракона» – азиаты такое любят. Но компания DeepMind из Великобритании, которая сейчас принадлежит Google, сделали свой самообучающийся алгоритм, который не разбирался в самых крутых партиях в го, вообще ничего не знал об этих традициях, он учился играть заново, сам, поэтому многие решения этого алгоритма признавались просто дурацкими. Первый ход, который сделала эта программа, все специалисты по го сочли абсолютно проигрышным – но самое интересное, что в конце партии всё замкнулось именно на этот первый ход. Эта программа разрушила представление корейцев, японцев и китайцев о том, что такое го. И на сегодняшний момент всё обучение у них происходит только по играм этого алгоритма. А это что-то да значит: общеизвестно ведь, насколько трепетно консервативные азиаты относятся к своей истории. Побеждённый корейский гроссмейстер Ли Седоль объявил после исторической игры об уходе из этого спорта. Он сказал: «больше нет смысла соревноваться в том, в чём ты никогда не поднимешься на высоту». На даный момент технологии ушли далеко вперёд, и итог действительно известен заранее.
В следующем 2017 году та же компания DeepMind «выкатывает» новый алгоритм AlphaZero, который учился на играх с самим собой, проведя сотни тысяч «поединков». За 4 часа он обучился игре в шахматы, за 8 часов в го. И каждый раз немножко улучшал свой алгоритм. Научился играть и в сёги, и в шашки – не осталось ни одной настольной игры, которая не далась бы этому компьютеру. Для сравнения: DeepBlue 1997 года умел играть только в шахматы, а эта найросеть – может всё, потому что она не имеет чёткой инструкции, она адаптируется к правилам игры. Она может учить правила на ходу и в соответствии с ними выбирать правильные решения. И вот на сей раз DeepMind уже устроили не соревнование человека и машины, а соревнование двух алгоритмов. AlphaZero победил в борьбе с каждым чемпионом мира среди программ, и Stockfish, и Elmo, за 24 часа сражений с ними достигнув сверхчеловеческого уровня игры.
Компания DeepMind прекратила своё соревнование в играх и полностью переключилась на медицину. Те алгоритмы, которые были наработаны при помощи игр, сейчас используются для диагностирования рака. В 2017 году 18 топовых онкологов Китая проиграли в точности диагностики программе, построенной на этих алгоритмах. Она диагностировала на 7-15% точнее, в том числе потому, что использовала не двухмерные, а трёхмерные сканы МРТ.
В последний раз Deep Mind занялась геймерскими соревнованиями в 2019 году. Существует такая стратегическая игра StarCraft II от компании Blizzard. В Корее она приобрела статус просто культовый, там очень много подростков, которые реально зарабатывают на этой игре. У них есть крутые спонсоры из всяких мировых компаний. Очень долгое время считалось, что компьютерные игры, киберспорт, это слишком большая сложность для ИИ. Здесь чётких правил нет, вы должны одновременно атаковать противника, следить за своими ресурсами, простраивать свою базу, управлять своим юнитом. Но новая найронная сеть под названием AlphaStar просто в пух и прах разнесла двух топовых игроков StarCraft II, европейцев. Причём они признавали, что тактика и способ ведения боя нейросети полностью отличался от человеческого и не был понятен до конца. Она использовала некие новые модели игры, которые сейчас воспринимаются геймерами и применяются уже в матчах между людьми.
Мы можем многому научиться у ИИ, потому что он выходит из привычной нам плоскости мышления. Его мышление не ограничено нашими стереотипами и рамками.
Очень интересная игра от компании Unity, графический движок Obstacle Tower Challenge поставил, впрочем, ИИ перед новым вызовом. Это трёхмерная игра-лабиринт, и нужно дойти до сотого уровня башни – за это была предусмотрена премия 100 тысяч долларов. Самые крутые игроки доходили до 10-го. А компьютер дошёл до 19-го. Игра оказалась очень сложной и процедурно генерируемой: не было такого, что уровни повторялись два раза подряд. Каждый раз даже разработчики не знали, как будет выглядеть следующий уровень, потому что создание уровня происходило непосредственно во время игры, и игра могла адаптироваться. Соответственно, даже самые крутые нейронные сети проходили эту игру только до 19 уровня.
На этом видео https://youtu.be/gn4nRCC9TwQ вы видите очень интересный пример, где нейронная сеть учится передвигаться, будучи перемещённой в реальную физическую обстановку. То есть здесь сила трения, сила гравитации, момент импульса полностью соответствуют реальным, просто они простроены в программной среде. Изначально нейросеть не умела ничего – у неё были просто ноги. И она сама научилась не просто ходить, а ещё и бегать, преодолевать препятствия, перепрыгивать большую дистанцию, ходить по пересечённой местности. Ребёнок точно так же учится ходить, процесс идентичен, что настройка нашей нейросети, что настройка искусственной нейросети. Но дети-то учатся ходить годами, а нейросеть научилась за считанные дни. Дело в том, что у нее было гораздо больше попыток и она могла этим заниматься постоянно, без перерывов на сон, еду и отдых. Да, и ей не надо было заранее описывать, как подниматься по лестнице – она может сама научиться! Поэтому я с предвосхищением жду следующее поколение роботов…
При «дип фейки» скандал отгремел уже почти год назад, когда нейросеть могла смоделировать видео любого политика, говорящего какую угодно чушь. Но вот это видео https://youtu.be/5rPKeUXjEvE, на котором лицо Джона Малковича перетекает в лицо актёра из «Король говорит», потом в Аль Пачино, «Люди в чёрном», Джорджа Клуни, Энтони Хопкинса, Моргана Фримана, «Во все тяжкие», Кристофа Вальца, Джонни Кэша, Гэндальфа и так далее – оно меня просто потрясло! Это настоящий актёр, который менял свой голос, но лица ему подстраивала нейросеть. Это означает одно: кинокомпаниям уже совсем скоро не надо будет тратить миллионы долларов за привлечение ДиКаприо в свой фильм, а можно будет просто купить за пару тысяч его лицо и сделать электронного ДиКаприо. Уже сейчас можно существенно сэкономить на гриме, что и продемонстрировал фильм «Ирландец», который будет номинироваться в этом году на «Оскар»: Де Ниро и Джонни Кэша полностью омолодили без помощи грима, а только использованием ИИ.
Следующее видео https://youtu.be/p3HWpBScjpA слабонервным просьба не смотреть. Это, грубо говоря, смерть нейронной сети. Справа нейроны, которые потихонечку отключаются, а слева изображение человека, по мере того как оно генерируется и страдает от отключения разных нейронов. Мы видим выцветание изображения, у него теряются мелкие детали, и со временем полное преображение. «Сон умирающей нейросети» похож на те процессы, которые происходят у пожилых людей – старческая деменция выглядит примерно вот так с научной точки зрения. То есть это реально слабоумие нейронной сети, в результате которого от симпатичного портрета девушки остаётся вот этот Франкенштейн.
Мой вывод такой. Все видели на картинках, какие орудия труда мы использовали 2,5 млн лет до нашей эры. Животные, которые их использовали, ещё не были людьми. Если мы возьмём другую картинку, на которой изображён сборочный цех крупного производства с роботами и немного абстрагируемся, то мы поймём, что это одно и то же. Роботы, как и допотопные орудия труда, созданы, чтобы нам меньше работать. Лень двигает прогресс. ИИ – это просто следствие развития нашей лени. Сначала мы думали, что хотим меньше работать, потом мы поняли, что мы хотим вообще не работать, а теперь мы понимаем, что мы и думать-то не хотим. Знаете, у пауков есть внешнее пищеварение: они впрыскивают свои желудочные соки в жертву и потом просто всасывают уже переваренный материал – так и у нас: будет просто внешнее мышление. Зачем думать головой, если мы создали смартфончик, который думает за нас.
__________________________
Читайте нас в телеграм
https://t.me/granitnauky
Поделиться ссылкой:
Моцарт, Стив Райх, Йоко Оно и другие авторы арт-генераторов в обзоре Алексея Шульгина
Состязания роботов-гитаристов, которыми хвалился Вертер в «Гостье из будущего», уже устраиваются – искусство вполне по силам машинам. По просьбе «Афиши Daily» Алексей Шульгин рассказал о том, что такое арт-генераторы, и привел примеры алгоритмических произведений у Йоко Оно, Стива Райха и «Яндекса».
В «Электромузее», входящем в объединение «Выставочные залы Москвы», открылась выставка «Автоматическая душа» — об алгоритмическом искусстве, арт-генераторах, машинной музыке. Тема скользкая: искусство, созданное с помощью компьютера, пока не получило того же статуса, что и искусство обычное, человеческое. Порой сами художники не могут с уверенностью сказать, кто автор их произведения — они или машина. Куратор выставки медиахудожник Алексей Шульгин, читающий в Школе Родченко курс по алгоритмическому искусству, объясняет, что такое арт-генераторы и почему за ними будущее.
«Музыкальная игра в кости» («Musikalisches Würfelspiel»)
Вольфганг Амадей Моцарт, 1770–1780-е
На австрийском телеканале показали, как играть в игру, придуманную Моцартом
Первый в истории человечества арт-генератор создал Моцарт — с его помощью он сочинял менуэты. Дело в том, что музыка сама по себе алгоритмична. Все в ней подчиняется каким-то законам: размер, темп, обязательные части, такт и прочее. И все менуэты во времена Моцарта создавались в рамках менуэтного канона, в котором присутствовали строгие ограничения. А если присутствуют ограничения, то разнообразие достигается за счет вариативности. Видимо, автор увидел, что разные фрагменты менуэтов можно менять друг с другом. Для выбора фрагмента Моцарт придумал кидать игральные кости. Выпавшее число определяло номер музыкального фрагмента — уже сочиненного и отложенного впрок, — который должен стать частью пьесы.
Студенты в Школе Родченко, где я читаю курс в том числе и про алгоритмическое искусство, конечно, от такого офигевают. Для них все эти понятия — генератор случайных чисел, рандомность — современные термины. Но тут выясняется, что ими пользовался Моцарт еще в XVIII веке! На нашей выставке «Музыкальная игра в кости» будет представлена просто и без изысков. Подходишь к тачскрину, нажимаешь кнопку, а тебе автоматом генерируется менуэт. Важный вопрос, который нужно самому себе задать в этот момент, звучит так: а кто автор этих произведений? Работая с программным обеспечением, мы не являемся однозначными авторами того, что делаем. Кто-то ведь уже написал этот самый софтвар — и автоматически стал нашим соавтором. Моцарт — автор несколько музыкальных фрагментов, он же придумал, как выбрать из них один, но является ли он автором каждого сгенерированного произведения? Может, автор тот, кто бросил кости и инициировал создание произведения?
«Уральские напевы»
Рудольф Зарипов, 1959
Зарипов за работой
Советский математик и программист создал первый арт-генератор в СССР. Впервые об автоматизированном способе сочинения музыки он задумался еще во время учебы в музыкальном училище, но к созданию его приступил уже в аспирантуре, работая на ЭВМ «Урал». Машинное конструирование мелодий долго не шло на лад — Зарипов видел бесконечное многообразие мелодических оборотов, но никак не мог найти одну изящную формулу, все их объединяющую. И только в 1959-м алгоритм наконец был написан, и машина «сочинила» три вальса и несколько маршей. Сам Рудольф Зарипов называл эти музыкальные произведения «Уральскими напевами» — в честь композитора, то есть машины.
Про Зарипова есть один момент интересный. Когда он начал создавать компьютерную музыку, его страшно клеймили советские искусствоведы. Говорили, что в этой музыке нет человека, что машины не могут делать искусство. И тогда он на большом симпозиуме, где были и композиторы, и музыканты, и ученые, устроил слепое прослушивание: взял несколько произведений, написанных машиной, и несколько произведений современных советских композиторов. Не объявляя, человек это написал или машина, он ставил одно произведение за другим, а аудитория оценивала их по разным критериям. В итоге средняя оценка машинного искусства оказалась выше, чем оценка искусства человеческого. То есть людям больше понравилось то, что машина написала. Зарипов все документировал — много писал в журналы «Знание — сила», «Музыка и время». У нас выставке будет представлено одно произведение из «Уральских напевов».
«Instructions»
Йоко Оно, 1961
Здесь и далее – инструкции Йоко Оно
1 из 4Вдова Джона Леннона точно так же, как и Моцарт, казалось бы, совсем из другой области. Она никогда не занималась алгоритмическим искусством — ее стихия концептуализм. В начале 1960-х у Йоко был проект: она сочиняла и печатала на листах бумаги коротенькие инструкции по созданию произведений. То есть фактически писала код, который можно выполнить, в результате чего может родиться произведение. Например, была такая инструкция: «Вырежи отверстие в сумке, наполненной разными семенами, и помести эту сумку туда, где есть ветер». Фактически это доказывает, что ноги генеративного искусства растут из концептуализма. Однако арт-истеблишмент во все времена принижал значение медиаискусства, в том числе компьютерного, и потому связь эта для многих не так очевидна. Хотя на самом деле одно перетекает в другое совершенно естественным образом.
Есть и другие примеры. Например, работы американского художника Ла Монте Янга — композитора, экспериментатора. В 1960-м он создал произведение, которое так и называлось «Draw a Straight Line and Follow It». А это уже чистый линк между концептуализмом и алгоритмическим искусством.
Исполнение «Compositions 1961» Янга в Университете Хаддерсфилда, Англия
Конечно, в корне алгоритмического искусства не один только концептуализм. Вариативность заложена в природе любого художественного творчества. Если мы возьмем, к примеру, работы художника Модильяни, то увидим, что они все очень похожие: голые женщины лежат или сидят, одинаковый тип лица, одинаковые фигуры. Видно, что есть некая основа, вокруг которой развиваются вариации. Это значит, что в голове у художника Модильяни была программа с неким генератором случайных чисел: тут она потолще, тут похудее, тут более вытянутая, смотрит немножко сюда или туда. У любого художника, у которого есть свой узнаваемый стиль, в голове сидит алгоритм, по которому он работает. Он сам его создает и сам осуществляет.
Но не всегда непосредственно собственными руками. Возьмем Дэмиена Херста, у которого есть серия работ с точечками, с кружочками цветными, которые рисовали на фабрике другие художники. То есть тут уже он сам взял алгоритм и выдал его другим художникам, которые нарисовали по нему картины. И это, как и в случае с Модильяни, тоже своеобразное алгоритмическое искусство. Жаль только, что алгоритм в голове Модильяни уже не прочтешь.
«Clapping Music»
Стив Райх, 1972
Знаменитый американский композитор-минималист Стив Райх придумал алгоритм создания минималистической музыки. Вернее, не сам придумал, а скорее позаимствовал в традиционной африканской и балинезийской музыке, которую изучал в течение своей жизни. Самая известная композиция Стива Райха, в которой он использует индонезийский народный прием, известный как «сдвиг по фазе» (phase shifting), — это «Clapping Music». Вот музыкальная фраза, она исполняется синхронно двумя музыкантами, восемь раз она повторяется, а на девятый — один исполнитель сдвигается на один такт, потом через восемь повторений сдвигается еще раз и так далее. Вообще вся минималистическая музыка устроена примерно похоже — почти везде заданы паттерны и алгоритм, по которому они воспроизводятся.
«Magic Hand of Chance»
Роман Веростко, 1982
Американский художник Роман Веростко знаменит тем, что в начале 1980-х, используя тригонометрические формулы, научил компьютер рисовать абстрактные картины. Сейчас уже понятно, что задать компьютеру код, выполняя который он изобразит синусоиду, не особенно и трудно. Но Веростко был одним из первых, кто осмелился заявить, что красота математической формулы и синусоиды — это тоже искусство. К сожалению, до сих пор это не общепринятый факт.
Проблема в том, что даже в модернистском искусстве очень важна фигура автора — героя, который ниспровергает старое искусство и представляет новое. Вся западная история искусств холила и лелеяла образ героя, а у Веростко художник превращается в программиста и в соавторы себе берет компьютер, который все рисует, и плоттер, который все печатает. Такая постановка вопроса идет немного вразрез с героическим опытом человечества. И поэтому надо принять, что до сих пор алгоритмическое искусство не признано, не выставляется на биеннале, и не берется в экспозиции музеев. Несмотря на это, Роман Веростко в конце концов стал признанным художником, и сейчас продолжает работать, но уже на новом технологическом уровне, с использованием современного программного обеспечения.
«n-Generate»
2003
Группа дизайнеров из Сан-Франциско в 2003 году объявила о выпуске программы для генерирования графического дизайна. Казалось бы, что такого. Ну что такое дизайн? Шрифты, картинки, стили, какие-то плашечки-вставочки, которые распределяются по всем известным законам красоты на листе заданного формата? Конечно же, все это давно было пора загнать в машину, приладить генератор случайных чисел, чтобы она как-то заполняла плоскость листа, и нажать «Пуск». Ничего сложного. Дизайнеры из Сан-Франциско не только произвели на свет такой генератор, но и написали к нему манифест: дизайнеры, трепещите, роботы скоро вас заменят. Но парадокс был в том, что они сами были дизайнерами. В какой-то момент до них дошло, что они сами себя подставили (а может, владелец их компании первым про это догадался). В общем, они ужаснулись и не стали дорабатывать программу.
А зря. Вообще говоря, при желании, если оно будет у кого-то когда-то, «n-Generate» можно восстановить. Но — и тут гадать даже нечего — будет давление со стороны дизайнерского сообщества. И так ходят пугающие разговоры про то, что роботы заменят человека. Билл Гейтс даже выступил с предложением облагать налогами роботов, уже заменяющих людей. Наконец это стало большой проблемой. Искусственный интеллект вместе с робототехникой может приблизить будущее. В Китае, на фабрике, где собирают смартфоны, уже 50% людей заменены машинами, и владельцы хотят довести эту цифру до 90%. Сборка смартфонов не так уже далека от производства дизайна. Большинство потребителей — и техники, и дизайна — средний уровень вполне устраивает. Сколько же их, посредственных дизайнеров, прямо сейчас сидит и клепает какую-то рутину, которую машина вполне может клепать сама!
То же и с искусством. Подавляющее большинство произведений искусства хреновое, вторичное. Молодые художники что-то такое где-то увидели, повторили и решили, что это и есть искусство. То есть идей новых свежих мало носится в воздухе, и всех этих художников можно заменить роботами. Нас всех заменят. И вас. И роботы-журналисты уже пишут статьи. Вы просто не хотите смотреть правде в глаза — не верите, что вас заменит робот. Я тоже не хочу, но это случится рано или поздно. Нужно перестраиваться, нужно выходить из зоны комфорта. Понятно, что хочется, чтобы талантливые художники водили кистью по холсту. Мы с этим выросли, к этому привыкли. И только в этом проблема. А будущее, оно все равно наступит. Прежние парадигмы отменятся или претерпят существенные изменения.
«Нейронная оборона»
«Яндекс», 2016
И последнее: прошлым летом сотрудники «Яндекса» Алексей Тихонов и Иван Ямщиков выпустили альбом «Нейронная оборона», состоящий из песен и стихотворений, написанных алгоритмом нейронных сетей на основе анализа творчества Егора Летова. Понятно, что это была оригинальная и не лишенная юмора рекламная кампания «Яндекса», но меня это заинтересовало.
Егор Летов, конечно же, перевернулся в гробу, а его поклонники, естественно, очень оскорбились. Когда я ставил сгенерированные компьютером песни в духе «ГрОб» студентам Школы Родченко, они начинали голосить: «Нет, это не то!» А когда я их спросил: но вот если бы вы не знали, что это компьютер написал, если бы вам просто сказали — новые, ранее не издававшиеся песни Летова, — что бы тогда? И они замялись. Для меня вся эта история говорит, с одной стороны, о новых способах создания произведений, а с другой — о тенденции, которая уже давно дает о себе знать: корпорация и художник сливаются в одно целое. Это и не плохо, и не хорошо. Просто так есть.
Brave Designers | Подборка Discover Weekly от Spotify: как машинное обучение находит для нас новую музыку
Наука, которая стоит за персонализированными музыкальными рекомендациями
В этот понедельник — как и в любой другой понедельник — более 100 миллионов пользователей Spotify открыли новый плейлист, собранный специально для них. Это стандартный микс из 30 песен, которые они никогда не слушали раньше, но, вероятно, полюбят их. Это подборка Discover Weekly, и это — почти магия.
Я большая поклонница Spotify, особенно подборки Discover Weekly. Почему? Благодаря ей я чувствую, что меня видят как пользователя. Spotify знает о моих музыкальных предпочтениях больше, чем любой человек в моей жизни. И я восхищаюсь его способностью попадать в точку с треками, которые я сама бы не нашла и даже не догадалась бы искать.
Все те, кто живет под музыкально звуконепроницаемым куполом, — позвольте познакомить вас с моим лучшим виртуальным другом:
Как оказалось, я не одинока в своей одержимости Discover Weekly — пользователи без ума от нее, и это побудило Spotify полностью переосмыслить фокус и инвестировать больше ресурсов в создание плейлистов на основе алгоритмов.
It’s scary how well @Spotify Discover Weekly playlists know me. Like former-lover-who-lived-through-a-near-death experience-with-me well.
— Dave Horwitz (@Dave_Horwitz) October 27, 2015
Начинает пугать, как хорошо Discover Weekly знает меня. Как бывшая возлюбленная, которая прожила рядом со мной практически до смерти.
At this point @Spotify’s discover weekly knows me so well that if it proposed I’d say yes
— Amanda Whitbred (@amandawhitbred) August 18, 2016
Discover Weekly знает меня так хорошо, что если бы он предложил выйти замуж, я бы сказала «да».
Итак, как же Spotify магическим образом выбирает эти 30 песен для каждого человека каждую неделю? Давайте на секунду отвлечемся: посмотрим, как другие музыкальные сервисы создают подборки треков, и убедимся, что Spotify делает это лучше.
Краткая история создания подборок онлайн-музыки
Еще в 2000-х годах Songza запустила подборки — тогда они создавались для пользователей вручную. «Manual curation» означает, что команда «музыкальных экспертов» или других кураторов вручную собирала плейлисты, которые, по их мнению, звучали хорошо. Позже Beats Music использовала эту же стратегию. Ручная подборка работала неплохо, но все же она требовала времени на создание. В итоге она все равно была простой и не учитывала нюанса индивидуального музыкального вкуса каждого слушателя.
Как и Songza, Pandora была одним из первых игроков области. Ее подход был чуть более продвинутым — вручную тегировались «атрибуты песен». Это означало, что группа людей слушала музыку, выбирала кучу описательных слов для каждого трека и помечала треки этими словами. Затем код мог просто фильтровать базу песен по тегам для создания плейлистов с похожей музыкой.
Примерно в это же время появилось музыкальное агентство The Echo Nest от MIT Media Lab. Оно предложило гораздо более продвинутый подход к персонализированной музыке. Echo Nest использовали алгоритмы для анализа аудио- и текстового содержания музыки, и с помощью них можно было идентифицировать треки, делать персонализированную рекомендацию и создавать список воспроизведения.
Наконец, совсем другой подход предложил Last.fm, который существует и сейчас. Он заключается в использовании совместной фильтрации для идентификации музыки, которая может понравиться пользователям. Больше об этом через одно мгновение.
***
Итак, это способы, которые использовали другие музыкальные онлайн-сервисы. Но как Spotify придумал свою волшебную машину, которая, кажется, разбирается в индивидуальных вкусах пользователей гораздо лучше, чем любой из них?
3 типа рекомендаций, который использует Spotify
Фактически Spotify не использует какую-то революционную модель рекомендаций – вместо этого он смешивает лучшие стратегии других сервисов, и так получается уникальный и мощный механизм Discovery.
Чтобы создать Discover Weekly, используются три основных типа моделей рекомендаций:
- Совместная фильтрация (как у Last.fm) — анализ поведения пользователей и сопоставление вашего поведения с поведением других;
- Обработка естественного языка (NLP) — анализ текста;
- Аудиоанализ, или анализ самих звуковых дорожек.
Давайте внимательно рассмотрим каждую из них!
Модель № 1: Совместная фильтрацияДля начала немного контекста: многие люди, когда слышат слова «совместная фильтрация», думают о Netflix, поскольку они были одной из первых компаний, которая для создания рекомендаций использовала рейтинг, формирующийся из оценок — «похожим» пользователям рекомендуют одни фильмы.
После успешного опыта Netflix-модель быстро распространилась, и теперь она стала своего рода отправной точкой для тех, кто пытается создать сервис с рекомендациями.
В отличие от Netflix, у Spotify нет системы выставления оценок. Вместо этого Spotify учитывает неявные данные — в частности, сколько раз пользователь прослушал трек, добавил ли его в плейлист и посетил страницу исполнителя после прослушивания.
Но что такое совместная фильтрация и как она работает? Вот вам краткое и поверхностное объяснение с помощью диалога:
«— Мне нравятся треки P, Q, R, S! — Тогда послушай трек T!»
«— Мне нравятся треки Q, R, S, T! — Круто! Попробуй P!»
Что мы видим? У каждого из этих двух парней есть некоторые предпочтения: парень слева любит треки P, Q, R и S, а парень справа любит треки Q, R, S и T.
Совместная фильтрация использует эти данные, чтобы сказать: «Ммм. Ваши предпочтения совпадают в 3-х треках — Q, R и S — так что вы, вероятно, полюбите треки из плейлистов друг друга. Надо предложить вам те из них, что вы еще не слышали».
Поэтому парень справа послушает P, а парень слева — T. Просто, не так ли?
Но как Spotify использует этот метод на практике для вычисления миллионов треков, которые понравятся одним пользователям, анализируя предпочтения миллионов других?
… матричная алгебра, написанная с помощью библиотек Python!
На самом деле матрица, которую вы видите здесь, гигантская. Каждая строка — один из 140 миллионов пользователей Spotify (если вы используете Spotify, вы сами являетесь строкой в этой матрице), и каждый столбец представляет собой одну из 30 миллионов песен в базе данных Spotify.
Затем в библиотеке Python выполняется эта длинная сложная матричная факторизация:
Когда вычисление выполнено, мы получаем два вектора: здесь X и Y. X — пользовательский вектор, представляющий один вкус одного пользователя, а Y — вектор песни, представляющий «профиль» одной песни.
Теперь у нас есть 140 миллионов пользовательских векторов — по одному для каждого пользователя — и 30 миллионов векторов песен. Фактическое содержание этих векторов — всего лишь куча чисел, по сути бессмысленных, но чрезвычайно полезных в сравнении.
Чтобы найти пользователей, музыкальные предпочтения которых наиболее похожи на мои, совместная фильтрация сравнивает мой вектор с векторами других пользователей, и выявляет максимальные сходства. То же самое касается Y-вектора песен — вы можете сравнить вектор песни со всеми другими и выявить, какие песни больше всего похожи на выбранные вами.
Хорошая работа. Но в Spotify знали, что они могут сделать лучше, добавив еще один инструмент — NLP (обработка естественного языка).
Модель №2: Обработка естественного языка
В этой модели осуществляется обработка текстовых источников, как и заявлено в названии — это метаданные треков, новостные статьи, блоги и другие тексты в Интернете.
Обработка естественного языка (NLP) — способность компьютера понимать человеческую речь как она есть. Это обширное поле само по себе, часто эксплуатирующее API анализа чувств/эмоций.
Изучение точных механизмов NLP выходит за рамки темы этой статьи, но поверхностно его можно описать так: Spotify сканирует Интернет в поисках блог-статей и других текстов о музыке и выясняет, что люди говорят о конкретных исполнителях и песнях: какие прилагательные и высказывания часто фигурируют в обсуждениях этих песен и какие другие исполнители и песни упоминаются вместе с ними.
И хотя я не знаю особенностей того, как именно Spotify выбирает данные для дальнейшей обработки, я могу рассказать, как Echo Nest работал с ними. Они группировали данные в так называемые «культурные векторы» или топ-значения/определения. Каждый исполнитель и каждая песня имели тысячи определений, которые обновлялись ежедневно. Каждое определение имело «вес», выраженный в числовом коэффициенте. Он показывал, насколько важно описание, а именно: насколько высока вероятность того, что кто-то будет описывать музыку с помощью конкретного слова.
Далее, как и в совместной фильтрации, NLP использует эти определения и коэффициенты для создания векторной репрезентации песни, которая может быть использована для определения схожести двух композиций. Круто, правда?
Модель №3: Аудиоанализ
Сначала вопрос. Вы можете подумать: «Но у нас же и так достаточно данных, добытых с помощью первых двух методов. Зачем нам анализировать и саму музыкальную дорожку?»
Третий метод повышает точность рекомендательного сервиса. Но это не все — в отличие от первых двух, он учитывает и новые песни.
Такой пример: ваш друг-сонграйтер выложил на Spotify свою песню. Допустим, у него всего 50 прослушиваний, поэтому парадигма совместной фильтрации к нему не очень-то применима. Он также пока не упоминается нигде в Интернете, поэтому и второй метод не сможет его обработать. К счастью, третий метод позволяет избежать дискриминацию, и песня вашего друга может оказаться в плейлисте Discover Weekly вместе с хитами!
Теперь осталось ответить на вопрос «как»: как мы можем анализировать необработанные аудиоданные, которые кажутся настолько абстрактными?
— с помощью сверточных нейронных сетей!
Сверточные нейронные сети — это та же технология для распознавания лица. В случае Spotify они были изменены для использования в аудиоданных вместо пикселей. Вот пример архитектуры нейронной сети:
Эта особая нейронная сеть имеет четыре сверточных слоя (толстые полосы слева) и три плотных слоя (более узкие полосы справа). Входные данные — «аудиокадры» определенной длительности, которые связываются для формирования спектрограммы. Аудиокадры проходят через эти сверточные слои, и после последнего сверточного слоя вы можете увидеть слой «глобального временного пула», который объединяет всю ось времени, эффективно вычисляя статистику изученных функций в течение песни.
После обработки нейронная сеть выдает характеристики песни, как развитие во времени, тональность, настроение, темп и громкость. Ниже приведен график этих данных для 30-секундной вырезки трека «Around the World» Daft Punk.
Понимание ключевых характеристик песни позволяет Spotify выделять фундаментальные сходства между треками и, основываясь на истории прослушиваний, предлагать то, что пользователям вероятно понравится.
Вот так, если говорить в общих чертах, работает конвейер рекомендаций Discover Weekly.
Конечно, эти три метода рекомендаций связаны с гораздо более обширной экосистемой Spotify, которая включает в себя огромные объемы данных, использует множество кластеров Hadoop для масштабирования рекомендаций и заставляет эти алгоритмы обрабатывать гигантские матрицы, бесконечное количество музыкальных статей и еще большее количество аудиофайлов.
нейронных сетей для музыки: путешествие по истории | Джорди Понс
Многое произошло между новаторскими статьями, написанными Льюисом и Тоддом в 80-х, и нынешней волной композиторов GAN. На этом пути о работе коннекционистов забыли зимой, когда ИИ, очень влиятельные имена (например, Шмидхубер или Нг) внесли основополагающие публикации, а тем временем исследователи добились огромного прогресса.
Мы не будем рассматривать все статьи в области нейронных сетей для музыки или углубляться в технические детали, но мы рассмотрим, что мы считаем вехами, которые помогли сформировать текущее состояние музыкального ИИ — это хорошее оправдание. отдать должное этим диким исследователям, которые решили позаботиться о сигнале, который является не чем иным, как крутым.Давайте начнем!
Сокращения
AI — Искусственный интеллект
CNN — Сверточная нейронная сеть
GAN — Генеративная состязательная сеть
LSTM — Долгосрочная краткосрочная память (тип)
0009 рекуррентной нейронной сети
— Цифровой интерфейс музыкальных инструментов (символьное музыкальное представление в виде партитуры)
MLP — Многослойный персептрон
RNN — Рекуррентная нейронная сеть
VAE — Вариационные автокодеры
Многие миллионы лет назад давным-давно зима началась на Земле после удара крупного астероида.В результате этой катастрофы произошло внезапное массовое вымирание всех видов на Земле.
К счастью, нейронные сети, применяемые в музыке, во время зимы искусственного интеллекта имели другую веру. Этот период привел к серии ложных работ по алгоритмической композиции, которые поддерживали актуальность этой области с 1988 по 2009 год. Это вклад так называемых коннекционистов в нейронные сети и машинное обучение.
Однако эти ранние работы практически неизвестны большинству современных исследователей.
Эта первая волна работ была начата в 1988 году Льюисом и Тоддом, которые предложили использовать нейронные сети для автоматического сочинения музыки.
С одной стороны, Льюис использовал многослойный персептрон для своего алгоритмического подхода к композиции, названного «создание путем уточнения». По сути, это основано на той же идее, что и DeepDream: использование градиентов для создания искусства.
С другой стороны, Тодд использовал авторегрессивную нейронную сеть Джордана (RNN) для последовательной генерации музыки — принцип, который спустя столько лет остается в силе.Многие люди продолжали использовать эту идею на протяжении многих лет, в том числе: Экк и Шмидхубер, которые предложили использовать LSTM для алгоритмической композиции. Или, если обратиться к более поздней работе, модель Wavenet (которая «способна» генерировать музыку) также использует тот же причинный принцип.
Посмотрите, что старые коннекционистские идеи, которые Тодд и Льюис представили еще в 80-х годах для алгоритмической композиции, все еще актуальны и сегодня. Но если их принципы были правильными, почему они не добились успеха? Что ж, по словам Льюиса: «Было трудно что-либо вычислить.«В то время как один современный графический процессор в рабочей станции с глубоким обучением может иметь теоретическую производительность около 110 тфлопс, у VAX-11/780 (рабочая станция, которую он использовал в 1988 году для своей работы) было 0,1 мфлопс.
Но вернемся к работе Эка и Шмидхубера. В своей статье «Обнаружение временной структуры в музыке: блюз-импровизация с LSTM, » они пытаются решить одну из основных проблем, которые были (и остаются) в алгоритмической композиции музыки: отсутствие глобальной согласованности или структуры.
Чтобы решить эту проблему, они предложили использовать LSTM, которые предположительно лучше, чем обычные RNN для изучения более длительных временных зависимостей. Обратите внимание, что в результате этого эксперимента музыка стала одним из первых приложений LSTM!
Как звучит музыка, созданная с помощью LSTM? Может ли он создать разумно структурированный блюз? Судите сами!
До 2009 года (и помните, что до 2006 года Хинтон и его коллеги не нашли систематического способа обучения глубоких нейронных сетей с помощью сетей глубоких убеждений) большинство работ было посвящено проблеме алгоритмической композиции музыки.В основном они пытались сделать это через RNN.
Но было одно исключение.
Еще в 2002 году Марольт и его коллеги использовали многослойный персептрон (работающий поверх спектрограмм!) Для задачи обнаружения начала нот. Это был первый раз, когда кто-то обрабатывал музыку в несимволическом формате. Это положило начало новой исследовательской эре: гонка стала первой, кто решит любую задачу на основе сквозного обучения. Это означает изучение системы (или функции) сопоставления, способной решать задачу непосредственно из необработанного звука, в отличие от решения ее с использованием специальных функций (например, спектрограмм) или символических музыкальных представлений (например, партитур MIDI).
В 2009 году зима AI закончилась, и первые работы по глубокому обучению начали оказывать влияние на сферу музыки и аудио AI.
Люди начали решать более сложные задачи (например, тегирование музыкальных аудиозаписей или распознавание аккордов) с помощью классификаторов глубокого обучения.
Следуя подходу Хинтона, основанному на предварительном обучении глубоких нейронных сетей с глубокими сетями убеждений, Ли и его коллеги (среди них Эндрю Нг) построили первую глубокую сверточную нейронную сеть для классификации музыкальных жанров.Это фундаментальная работа, которая заложила основу для поколения исследователей глубокого обучения, которые потратили огромные усилия на разработку более совершенных моделей для распознавания высокоуровневых (семантических) концепций из музыкальных спектрограмм.
Однако не все были удовлетворены использованием моделей на основе спектрограмм. Примерно в 2014 году Дилеман и его коллеги начали изучать амбициозное исследовательское направление, которое было представлено миру как Сквозное обучение для музыкального звука . В этой работе они исследуют идею прямой обработки сигналов для задачи тегирования музыкального аудио — что имело определенный успех, поскольку модели на основе спектрограмм по-прежнему превосходили модели на основе форм сигналов.В то время не только модели были недостаточно зрелыми, но и обучающих данных было мало по сравнению с объемами данных, к которым сейчас есть доступ у некоторых компаний. Например, недавнее исследование, проведенное на Pandora Radio, показывает, что модели на основе формы волны могут превзойти модели на основе спектрограмм при условии, что доступно достаточно данных для обучения.
Другая исторически примечательная работа принадлежит Хамфри и Белло (2012), которые в те дни предлагали использовать глубокие нейронные сети для распознавания аккордов.Они убедили ЛеКуна стать соавтором « Deep Learning for Music MANIFESTO» — см. Его настоящее (немного другое) название в ссылках! В этой статье они объясняют исследователям музыкальных технологий, что изучать (иерархические) представления из данных — неплохая идея — и, что интересно, они утверждали, что сообщество уже использовало глубокие (иерархические) представления!
В общих чертах, можно разделить эту область на две основные области исследований: поиск музыкальной информации, целью которого является создание моделей, способных распознавать семантику, присутствующую в музыкальных сигналах; и алгоритмическая композиция с целью компьютерного создания новых привлекательных музыкальных произведений.
Обе области в настоящее время процветают, а исследовательское сообщество неуклонно развивается!
Например, в области поиска музыкальной информации: хотя нынешние глубокие нейронные сети достигли разумного успеха, последние работы все еще расширяют границы возможного за счет улучшения архитектур, определяющих эти модели.
Но настоящие исследователи не только стремятся улучшить характеристики таких моделей. Они также изучают, как повысить его интерпретируемость или как уменьшить объем вычислений.
Кроме того, как упоминалось ранее, существует большой интерес к разработке архитектур, способных напрямую работать с сигналами для большого разнообразия задач. Однако исследователям пока не удалось разработать общую стратегию, которая позволяет моделям на основе формы волны решать широкий спектр проблем — то, что позволило бы широко применять сквозные классификаторы.
Другая группа исследователей также исследует край науки, чтобы улучшить методы алгоритмической композиции.Помните, что еще в 80-х (Тодд и Льюис) и в начале 2000-х (Экк и Шмидхубер) использовались довольно упрощенные авторегрессивные нейронные сети. Но сейчас время для современных генеративных моделей, таких как GAN (генеративные состязательные сети) или VAE (вариационные автокодировщики).
Достаточно интересно: эти современные генеративные модели не только используются для составления новых партитур в символическом формате, но и такие модели, как WaveGAN или Wavenet, могут быть инструментом для исследования новых тембральных пространств или для рендеринга новых песен непосредственно в области формы волны (в отличие от сочинять новые MIDI-партитуры).
Нейронные сети теперь предоставляют инструменты (и новые подходы!), Которые ранее были недостижимы. Такие задачи, как разделение источников музыки или транскрипция музыки (которые считаются Святым Граалем среди музыкальных технологов), теперь пересмотрены с точки зрения глубокого обучения. Пора пересмотреть, что возможно, а что нет, и простое разделение нейронных сетей для музыки на две области слишком недальновидно. Новое поколение исследователей в настоящее время ищет инновационные способы соединить кусочки, экспериментирует с новыми задачами и использует нейронные сети в качестве инструмента для творчества, что может привести к новым способам взаимодействия людей с музыкой.
Вы хотите быть одним из тех, кто формирует это будущее?
Пропустите этот раздел, если вы не мотивированный ученый.
Этот пост основан на учебной презентации, которую я подготовил несколько месяцев назад.
Статьи Льюиса и Тодда из 80-х:
Впервые кто-то использовал LSTM для музыки:
- Eck & Schmidhuber, 2002 — «Поиск временной структуры в музыке: импровизация блюза с рекуррентными сетями LSTM» в IEEE Workshop on Neural Сети для обработки сигналов .
Первый раз, когда кто-то обработал спектрограммы с помощью нейронных сетей:
Первый раз, когда кто-то построил классификатор музыкальных жанров с помощью нейронных сетей — на основе сетей глубоких убеждений Хинтона для неконтролируемого предварительного обучения:
Когда кто-то впервые построил конец- сквозной музыкальный классификатор:
Недавнее исследование, проведенное на Pandora Radio, показывающее потенциал сквозного обучения в масштабе:
Хамфри и Белло (2012) проделали некоторую работу по распознаванию аккордов и написали глубокое обучение для музыкального манифеста :
Чтобы узнать больше о продолжающейся дискуссии о том, как улучшить текущие архитектуры, см .:
Некоторые современные генеративные модели для алгоритмической композиции (в основном GAN и VAE):
И некоторые работы, непосредственно синтезирующие музыкальный звук (waveGAN и Wavenet, в основном):
Благодарности
Сообщение написано в сотрудничестве с Exxact (@Exxactcorp).Большое спасибо JP Lewis и Peter M. Todd за ответы на электронные письма и Yann Bayle за ведение этого (буквально) потрясающего списка статей по глубокому обучению, применимых к музыке.
Музыкальный автомат
Кураторские образцы
На входе Jukebox с указанием жанра, исполнителя и текста песни воспроизводится новый музыкальный образец, созданный с нуля. Ниже мы показываем некоторые из наших любимых образцов.
Чтобы прослушать все не прошедшие отбор сэмплы, воспользуйтесь нашим обозревателем сэмплов.
Изучить все образцыСодержание
- Мотивация и предыдущая работа
- Подход
- Ограничения
- Направления будущего
- Хронология
Мотивация и предшествующая работа
Автоматическая генерация музыки насчитывает более полувека.Известный подход состоит в том, чтобы создать музыку символически в форме рояля, который определяет время, высоту тона, скорость и инструмент каждой ноты, которую нужно сыграть. Это привело к впечатляющим результатам, таким как создание хоралов Баха, полифонической музыки с использованием нескольких инструментов, а также небольших музыкальных произведений.
Но у символических генераторов есть ограничения — они не могут улавливать человеческие голоса или многие из более тонких тембров, динамики и выразительности, которые необходимы для музыки. Другой подход — моделировать музыку напрямую как необработанный звук.Создание музыки на уровне звука является сложной задачей, поскольку последовательности очень длинные. Типичная 4-минутная песня с качеством CD (44 кГц, 16 бит) имеет более 10 миллионов временных шагов. Для сравнения, у GPT-2 было 1000 временных шагов, а у OpenAI Five — десятки тысяч временных шагов за игру. Таким образом, чтобы изучить семантику музыки высокого уровня, модели придется иметь дело с зависимостями на очень большом расстоянии.
Одним из способов решения проблемы длинного ввода является использование автокодировщика, который сжимает необработанный звук в пространство меньшей размерности, отбрасывая некоторые несущественные для восприятия биты информации.Затем мы можем обучить модель генерировать звук в этом сжатом пространстве и повышать дискретизацию до исходного звукового пространства.
Мы выбрали работу над музыкой, потому что хотим и дальше расширять границы генеративных моделей. В нашей предыдущей работе над MuseNet мы исследовали синтез музыки на основе больших объемов MIDI-данных. Теперь, когда речь идет о необработанном звуке, наши модели должны научиться справляться с большим разнообразием, а также со структурой очень большого диапазона, а область исходного звука особенно не прощает ошибок в краткосрочной, среднесрочной или долгосрочной перспективе.
Необработанный звук 44,1 тыс. Отсчетов в секунду, где каждый отсчет представляет собой число с плавающей запятой, которое представляет амплитуду звука в данный момент времени
Кодирование с использованием CNN (сверточные нейронные сети)
Сжатый звук 344 отсчета в секунду, где каждый отсчет представляет собой 1 из 2048 возможных токенов словаря
Создавайте новые паттерны из обученного трансформатора на основе текстов песен.
Новый сжатый звук 344 отсчета в секунду
Повышайте дискретизацию с помощью трансформаторов и декодируйте с помощью CNN
Новый необработанный звук 44.1k выборок в секунду
Подход
Сжатие музыки в дискретные коды
Модель автокодераJukebox сжимает звук до дискретного пространства, используя подход на основе квантования, называемый VQ-VAE. Иерархические VQ-VAE могут генерировать короткие инструментальные пьесы из нескольких наборов инструментов, однако они страдают от коллапса иерархии из-за использования последовательных кодеров в сочетании с авторегрессивными декодерами. Упрощенный вариант под названием VQ-VAE-2 позволяет избежать этих проблем за счет использования только кодеров и декодеров с прямой связью, и они показывают впечатляющие результаты при создании изображений с высокой точностью воспроизведения.
Мы черпаем вдохновение из VQ-VAE-2 и применяем их подход к музыке. Мы модифицируем их архитектуру следующим образом:
- Чтобы облегчить коллапс кодовой книги, характерный для моделей VQ-VAE, мы используем случайные перезапуски, при которых мы произвольно сбрасываем вектор кодовой книги в одно из закодированных скрытых состояний всякий раз, когда его использование падает ниже порогового значения.
- Чтобы максимально использовать верхние уровни, мы используем отдельные декодеры и независимо реконструируем входные данные из кодов каждого уровня.
- Чтобы модель могла легко восстанавливать более высокие частоты, мы добавляем спектральные потери, которые уменьшают норму разницы входных и восстановленных спектрограмм.
Мы используем три уровня в нашем VQ-VAE, показанном ниже, которые сжимают необработанный звук 44 кГц в 8x, 32x и 128x, соответственно, с размером кодовой книги 2048 для каждого уровня. Это понижающая дискретизация теряет большую часть деталей звука и звучит заметно шумно, когда мы спускаемся дальше по уровням. Однако он сохраняет важную информацию о высоте, тембре и громкости звука.
Каждый уровень VQ-VAE независимо кодирует вход. Кодирование нижнего уровня обеспечивает реконструкцию самого высокого качества, в то время как кодирование верхнего уровня сохраняет только важную музыкальную информацию.
Для создания новых песен каскад преобразователей генерирует коды от верхнего до нижнего уровня, после чего декодер нижнего уровня может преобразовать их в необработанный звук.
Генерация кодов с помощью трансформаторов
Затем мы обучаем предыдущие модели, целью которых является изучение распределения музыкальных кодов, закодированных с помощью VQ-VAE, и создание музыки в этом сжатом дискретном пространстве. Как и VQ-VAE, у нас есть три уровня априорных значений: априор верхнего уровня, который генерирует наиболее сжатые коды, и два апсэмплинга, которые генерируют менее сжатые коды, обусловленные вышеизложенным.
Предыдущие модели верхнего уровня моделируют длинную структуру музыки, и сэмплы, декодированные с этого уровня, имеют более низкое качество звука, но захватывают семантику высокого уровня, такую как пение и мелодии. Средние и нижние апсэмплинги добавляют локальные музыкальные структуры, такие как тембр, значительно улучшая качество звука.
Мы обучаем их как модели авторегрессии, используя упрощенный вариант разреженных трансформаторов. Каждая из этих моделей имеет 72 уровня факторизованного самовнимания в контексте из 8192 кодов, что соответствует примерно 24 секундам, 6 секундам и 1.5 секунд сырого звука на верхнем, среднем и нижнем уровнях соответственно.
После того, как все априоры обучены, мы можем генерировать коды с верхнего уровня, повышать их дискретизацию с помощью повышающих дискретизаторов и декодировать их обратно в необработанное звуковое пространство с помощью декодера VQ-VAE для семплирования новых песен.
Набор данных
Чтобы обучить эту модель, мы просканировали Интернет для создания нового набора данных из 1,2 миллиона песен (600 000 из которых на английском языке) в сочетании с соответствующими текстами песен и метаданными из LyricWiki.Метаданные включают исполнителя, жанр альбома и год песен, а также общие настроения или ключевые слова списка воспроизведения, связанные с каждой песней. Мы тренируемся на 32-битном необработанном звуке с частотой 44,1 кГц и выполняем увеличение данных путем случайного понижающего микширования правого и левого каналов для получения монофонического звука.
Художественная и жанровая подготовка
Преобразователь верхнего уровня обучен задаче прогнозирования сжатых звуковых токенов. Мы можем предоставить дополнительную информацию, например об исполнителе и жанре для каждой песни.У этого есть два преимущества: во-первых, это уменьшает энтропию предсказания звука, поэтому модель может достичь лучшего качества в любом конкретном стиле; во-вторых, во время генерации мы можем управлять моделью для генерации в выбранном нами стиле.
Этот t-SNE ниже показывает, как модель учится бесконтрольно объединять похожие артисты и жанры, близкие друг к другу, а также вызывает некоторые удивительные ассоциации, такие как близость Дженнифер Лопес к Долли Партон!
Текст песни Conditioning
В дополнение к определению исполнителя и жанра, мы можем предоставить больше контекста во время обучения, подготовив модель к тексту песни.Существенной проблемой является отсутствие хорошо согласованного набора данных: у нас есть тексты только на уровне песни без согласования с музыкой, и, таким образом, для данного фрагмента звука мы не знаем точно, какая часть текста (если есть) появляться. У нас также могут быть версии песен, которые не соответствуют лирическим версиям, как это может случиться, если данная песня исполняется несколькими разными артистами немного по-разному. Кроме того, певцы часто повторяют фразы или иным образом изменяют текст, что не всегда отражено в написанном тексте.
Чтобы сопоставить звуковые части с соответствующими текстами песен, мы начинаем с простой эвристики, которая выравнивает символы текста так, чтобы линейно охватить продолжительность каждой песни, и передаёт окно фиксированного размера символов, сосредоточенное вокруг текущего сегмента во время обучения. Хотя эта простая стратегия линейного выравнивания сработала на удивление хорошо, мы обнаружили, что она не работает для некоторых жанров с быстрой лирикой, таких как хип-хоп. Чтобы решить эту проблему, мы используем Spleeter для извлечения вокала из каждой песни и запускаем NUS AutoLyricsAlign для извлеченного вокала, чтобы получить точное выравнивание текста на уровне слов.Мы выбрали достаточно большое окно, чтобы текст песни с высокой вероятностью находился внутри него.
Чтобы следить за текстами песен, мы добавляем кодировщик для создания представления текстов песен и добавляем уровни внимания, которые используют запросы от музыкального декодера для обработки ключей и значений из кодировщика текстов. После обучения модель учится более точному выравниванию.
Согласование текста и музыки, полученное с помощью уровня внимания кодера-декодера
Внимание переходит от одного слова песни к другому по мере развития музыки, с некоторыми моментами неопределенности.
Ограничения
В то время как Jukebox представляет собой шаг вперед в музыкальном качестве, согласованности, длине аудиосэмпла и способности зависеть от исполнителя, жанра и текста, существует значительный разрыв между этими поколениями и музыкой, созданной людьми.
Например, хотя сгенерированные песни демонстрируют локальную музыкальную согласованность, следуют традиционным образцам аккордов и даже могут содержать впечатляющие соло, мы не слышим знакомые более крупные музыкальные структуры, такие как повторяющиеся припевы.Наш процесс понижающей и повышающей дискретизации привносит заметный шум. Улучшение VQ-VAE таким образом, чтобы его коды собирали больше музыкальной информации, помогло бы уменьшить это. Наши модели также медленно отбираются из-за авторегрессионного характера выборки. Для полной визуализации одной минуты звука с помощью наших моделей требуется около 9 часов, поэтому их пока нельзя использовать в интерактивных приложениях. Использование методов перегонки модели в параллельный пробоотборник может значительно увеличить скорость отбора проб.Наконец, в настоящее время мы обучаемся английским текстам и в основном западной музыке, но в будущем мы надеемся включить песни с других языков и частей света.
Направления будущего
Наша команда по работе с аудио продолжает работать над созданием аудиосэмплов, основанных на различных типах первичной информации. В частности, мы наблюдали ранний успех в MIDI-файлах и основных файлах. Вот пример необработанного аудиосэмпла, основанного на токенах MIDI. Мы надеемся, что это улучшит музыкальность сэмплов (так же, как обработка текстов улучшит пение), а также даст музыкантам больше контроля над поколениями.Мы ожидаем, что сотрудничество людей и моделей станет все более захватывающим творческим пространством. Если вы хотите поработать с нами над этими проблемами, мы будем нанимать.
По мере того, как генеративное моделирование в различных областях продолжает развиваться, мы также проводим исследования по таким вопросам, как предвзятость и права интеллектуальной собственности, и взаимодействуем с людьми, которые работают в тех областях, где мы разрабатываем инструменты. Чтобы лучше понять будущие последствия для музыкального сообщества, мы предоставили Jukebox первоначальный набор из 10 музыкантов из разных жанров, чтобы обсудить их отзывы об этой работе.Хотя музыкальный автомат — интересный результат исследования, эти музыканты не нашли его сразу применимым к своему творческому процессу, учитывая некоторые из его текущих ограничений. Мы подключаемся к более широкому творческому сообществу, так как думаем, что генеративная работа над текстом, изображениями и аудио будет продолжать улучшаться. Если вы заинтересованы в творческом сотрудничестве, чтобы помочь нам создавать полезные инструменты или новые произведения искусства в этих областях, сообщите нам об этом!
Регистрация Creative CollaboratorЧтобы связаться с соответствующими авторами, отправьте электронное письмо на адрес jukebox @ openai.com.
- Наша первая необработанная аудиомодель, которая учится воссоздавать такие инструменты, как фортепиано и скрипка. Мы пробуем набор данных рок- и поп-песен, и, на удивление, он работает.
- Мы собираем более крупный и разнообразный набор данных о песнях с ярлыками для жанров и исполнителей. Модель подбирает исполнителей и жанровые стили более последовательно с разнообразием, и при конвергенции также может создавать полноформатные песни с большой связностью.
- Мы масштабируем VQ-VAE от 22 до 44 кГц для достижения более высокого качества звука. Мы также масштабируем предыдущий верхний уровень от 1B до 5B, чтобы уловить увеличившуюся информацию. Мы видим лучшее музыкальное качество, чистое пение и большую слаженность. Мы также делаем новые дополнения к настоящим песням.
- Мы начинаем обучать модели с учетом слов, чтобы включить дополнительную информацию о кондиционировании. У нас есть только невыровненные тексты, поэтому модель должна научиться выравниванию и произношению, а также пению.
Хронология
MuseNet
Мы создали MuseNet, глубокую нейронную сеть, которая может генерировать 4-минутные музыкальные композиции с использованием 10 различных инструментов и может комбинировать стили от кантри до Моцарта и Битлз. MuseNet не был явно запрограммирован с учетом нашего понимания музыки, но вместо этого обнаружил закономерности гармонии, ритма и стиля, научившись предсказывать следующий токен в сотнях тысяч файлов MIDI. MuseNet использует ту же универсальную неконтролируемую технологию, что и GPT-2, крупномасштабная модель преобразователя, обученная предсказывать следующий токен в последовательности, будь то аудио или текст.
Образцы
Поскольку MuseNet знает множество разных стилей, мы можем сочетать поколения по-новому. Здесь модели даются первые 6 нот ноктюрна Шопена, но ее просят создать пьесу в стиле поп с фортепиано, барабанами, басом и гитарой. Модель удается убедительно сочетать два стиля, при этом полная полоса соединяется примерно на 30-секундной отметке:
Попробовать MuseNet
Мы очень рады видеть, как музыканты и не музыканты будут использовать MuseNet для создания новых композиций!
В простом режиме (отображается по умолчанию) вы услышите случайные некорректные сэмплы, которые мы предварительно сгенерировали.Выберите композитора или стиль, необязательно начало известной пьесы и начните создавать. Это позволяет вам изучить разнообразие музыкальных стилей, которые может создать модель. В расширенном режиме вы можете напрямую взаимодействовать с моделью. Завершение займет больше времени, но вы создадите совершенно новый предмет.
Некоторые из ограничений MuseNet включают:
- Инструменты, о которых вы просите, являются сильными предложениями, а не требованиями. MuseNet генерирует каждую заметку, вычисляя вероятности для всех возможных заметок и инструментов.Модель меняется, чтобы сделать ваш выбор инструмента более вероятным, но всегда есть шанс, что он выберет что-то другое.
- MuseNet переживает более трудные времена с нечетным сочетанием стилей и инструментов (например, Шопена с басом и барабанами). Поколения будут более естественными, если вы выберете инструменты, наиболее близкие к стилю композитора или группы.
Жетоны композиторов и инструментальных средств
Мы создали токены композитора и инструментария, чтобы дать больший контроль над типами семплов, генерируемых MuseNet.Во время обучения эти токены композитора и инструментария добавлялись к каждой выборке, чтобы модель научилась использовать эту информацию при составлении прогнозов заметок. Во время генерации мы можем затем настроить модель для создания сэмплов в выбранном стиле, начав с такой подсказки, как Rachmaninoff piano start:
Или по запросу группы Journey, с фортепиано, басом, гитарой и барабанами:
Мы можем визуализировать вложения из MuseNet, чтобы понять, чему научилась модель.Здесь мы используем t-SNE для создания двухмерной карты косинусного сходства различных музыкальных композиторов и встраиваний стилей.
Наведите указатель мыши на конкретного композитора или стиль, чтобы увидеть, как они соотносятся с другими.
Долгосрочная структура
MuseNet использует пересчитанные и оптимизированные ядра Sparse Transformer для обучения 72-уровневой сети с 24 головами внимания — с полным вниманием в контексте 4096 токенов. Этот длинный контекст может быть одной из причин, по которой он способен запоминать долгосрочную структуру произведения, как в следующем образце, имитирующем Шопена:
Он также может создавать музыкальные мелодические структуры, как в этом образце, имитирующем Моцарта:
Генерация музыки — полезная область для тестирования Sparse Transformer, поскольку она находится на среднем уровне между текстом и изображениями.Он имеет гибкую структуру токенов в виде текста (на изображениях вы можете просмотреть N токенов и найти строку выше, тогда как в музыке нет фиксированного числа для возврата к предыдущему такту). Тем не менее, мы легко можем услышать, фиксирует ли модель долгосрочную структуру порядка сотен или тысяч токенов. Гораздо очевиднее, если музыкальная модель искажает структуру, изменяя ритм, и менее ясно, если текстовая модель идет по короткому касанию.
Набор данных
Мы собрали данные обучения для MuseNet из множества различных источников.ClassicalArchives и BitMidi пожертвовали свои большие коллекции MIDI-файлов для этого проекта, и мы также нашли несколько коллекций в Интернете, включая джаз, поп, африканские, индийские и арабские стили. Дополнительно мы использовали набор данных MAESTRO.
Преобразователь обучается на последовательных данных: учитывая набор заметок, мы просим его предсказать предстоящую заметку. Мы экспериментировали с несколькими различными способами кодирования файлов MIDI в токены, подходящие для этой задачи. Во-первых, аккордовый подход, при котором каждая комбинация нот, звучащих одновременно, рассматривается как отдельный «аккорд», и каждому аккорду присваивается символ.Во-вторых, мы попытались сжать музыкальные паттерны, сосредоточив внимание только на начале нот, и попытались дополнительно сжать их, используя схему кодирования пар байтов.
Мы также попробовали два разных метода отметки времени: либо жетоны, которые были масштабированы в соответствии с темпом пьесы (так, чтобы жетоны представляли музыкальный ритм или долю доли), либо жетоны, которые отмечали абсолютное время в секундах. Мы остановились на кодировке, сочетающей выразительность с лаконичностью: объединение высоты тона, громкости и информации об инструменте в один токен.
bach piano_strings начало темпа90 фортепиано: v72: G1 фортепиано: v72: G2 фортепиано: v72: B4 фортепиано: v72: D4 скрипка: v80: G4 фортепиано: v72: G4 фортепиано: v72: B5 фортепиано: v72: D5 ожидание: 12 фортепиано : v0: B5 wait: 5 фортепиано: v72: D5 wait: 12 фортепиано: v0: D5 wait: 4 фортепиано: v0: G1 фортепиано: v0: G2 фортепиано: v0: B4 фортепиано: v0: D4 скрипка: v0: G4 фортепиано: v0: G4 ожидание: 1 фортепьяно: v72: G5 ожидание: 12 фортепьяно: v0: G5 ожидание: 5 фортепьяно: v72: D5 ожидание: 12 фортепьяно: v0: D5 ожидание: 5 фортепьяно: v72: B5 ожидание: 12 Кодирование сэмплов, объединяющее высоту тона, громкость и инструмент.
За время обучения мы:
- Транспонируйте ноты, повышая и понижая высоту звука (позже в процессе обучения мы уменьшаем количество транспонирования, чтобы поколения оставались в пределах диапазонов отдельных инструментов).
- Увеличивайте громкость, увеличивая или уменьшая общую громкость различных сэмплов.
- Увеличение времени (при кодировании абсолютного времени в секундах), эффективно немного замедляя или ускоряя части.
- Использовать перепутывание в пространстве для встраивания токена
Мы также создаем внутреннего критика: во время обучения модели просят предсказать, действительно ли данный образец взят из набора данных или это одно из собственных прошлых поколений модели.Эта оценка используется для выбора образцов во время генерации.
Вложения
Мы добавили несколько различных видов вложений, чтобы придать модели более структурный контекст. В дополнение к стандартным позиционным вложениям мы добавили изученное встраивание, которое отслеживает течение времени в данной выборке. Таким образом, все ноты, которые звучат одновременно, получают одинаковую временную привязку. Затем мы добавляем вложение для каждой ноты в аккорде (это имитирует относительное внимание, так как модели будет легче узнать, что примечание 4 должно возвращаться к примечанию 3 или, иначе, к примечанию 4 предыдущего аккорда).Наконец, мы добавляем два структурных вложения, которые сообщают модели, где находится данный музыкальный образец в более крупном музыкальном произведении. Одно вложение делит большую часть на 128 частей, а вторая кодировка — это обратный отсчет от 127 до 0 по мере приближения модели к (конечному) токену.
Мы рады слышать, что создают люди! Если вы создаете понравившуюся вещь, вы можете загрузить ее в бесплатный сервис, такой как Instaudio, а затем отправить нам ссылку в Твиттере (в демоверсии MuseNet есть кнопка твита, которая поможет с этим).
Если вы хотите узнать больше о музыкальной работе OpenAI, подайте заявку на присоединение к нашей команде. Пожалуйста, не стесняйтесь писать нам по электронной почте с предложениями по демоверсии MuseNet. Мы также будем рады услышать от вас, если вы заинтересованы в более глубоком сочинении с MuseNet или если у вас есть файлы MIDI, которые вы хотите добавить в обучающий набор.
MuseNet отыграл экспериментальный концерт 25 апреля 2019 года, который транслировался в прямом эфире на канале OpenAI в Twitch, и ни один человек (включая нас) раньше не слышал эти пьесы.AI собирается навсегда встряхнуть музыку — но не так, как вы думаете
Прогуляйтесь, Бибер. Отойди, Гага. И будь осторожен, Ширан. Искусственный интеллект здесь, и он приходит на вашу работу.
По крайней мере, это то, что вы могли бы подумать, рассмотрев постоянно растущую изощренность музыки, созданной с помощью искусственного интеллекта.
Хотя концепция машинной музыки существует с 1800-х годов (пионер компьютерных технологий Ада Лавлейс была одной из первых, кто написал на эту тему), фантазия стала реальностью в последнее десятилетие, когда такие музыканты, как Франсуа Паше, создали целую альбомы в соавторстве с AI.
Некоторые даже использовали искусственный интеллект для создания «новой» музыки из таких песен, как Эми Уайнхаус, Моцарт и Нирвана, передавая свой задний каталог в нейронную сеть.
Еще более странно то, что в июле страны по всему миру даже примут участие во втором ежегодном конкурсе AI Song Contest — конкурсе в стиле Евровидения, в котором все песни должны быть созданы с помощью искусственного интеллекта. (Если вам интересно, в 2020 году Великобритания набрала более нулевых баллов, заняв приличное 6 -е место).
Но станет ли эта технология когда-нибудь по-настоящему популярной? Неужели искусственный интеллект, как опасается художник Граймс, скоро «сделает музыкантов устаревшими?»
Чтобы ответить на эти и другие вопросы, мы встретились с профессором Ником Брайан-Киннсом, директором Центра медиа и технологий в области искусства Лондонского университета королевы Марии. Ниже он объясняет, как создается музыка искусственного интеллекта, почему эта технология не сокрушит творчество человечества и как роботы могут вскоре стать частью живых выступлений.
Насколько легко создавать музыку с искусственным интеллектом?Музыкальный ИИ использует нейронные сети, которые представляют собой действительно большие наборы битов компьютеров, которые пытаются имитировать работу мозга.По сути, вы можете направить в эту нейронную сеть много музыки, и она изучает закономерности — точно так же, как это делает человеческий мозг, постоянно показывая что-то.
Сложность современных нейронных сетей заключается в том, что они становятся все больше и больше. И людям становится все труднее и труднее понять, что они на самом деле делают.
Мы приближаемся к тому моменту, когда у нас есть по сути черные ящики, в которые мы вкладываем музыку, и выходит новая хорошая музыка. Но мы не совсем понимаем в деталях, что он делает.
Эти нейронные сети также потребляют много энергии. Например, если вы пытаетесь обучить ИИ анализировать поп-музыку за последние 20 лет, вы собираете все эти данные, а затем используете лот электричества для анализа и создания новой песни. В какой-то момент нам придется задаться вопросом, стоит ли воздействие на окружающую среду этой новой музыки.
Сможет ли ИИ в будущем когда-либо самостоятельно разрабатывать музыку?Я скептически отношусь к этому.Компьютер может легко записать сотни треков, но человек все еще может выбирать, какие из них ему нравятся, а какие — приятные .
В настоящий момент AI-музыка творится немного дыма и зеркал. Вы можете добавить задний каталог Эми Уайнхаус в ИИ, и получится много музыки. Но кто-то должен пойти и отредактировать это. Они должны решить, какие части им нравятся, а над какими ИИ нужно поработать немного больше.
Проблема в том, что мы пытаемся научить ИИ создавать музыку, которая нам нравится, но мы не позволяем ему создавать музыку, которая ему нравится.Может быть, компьютеру нравится другая музыка, нежели нам . Может быть, в будущем все ИИ будут слушать музыку вместе без людей.
Будет ли ИИ когда-либо создавать тексты, эмоционально значимые для людей?Я тоже скептически отношусь к этому вопросу. AI может создавать интересные тексты с интересным повествованием. Но тексты песен обычно основаны на жизненном опыте людей, на том, что с ними случилось.Люди пишут о любви, о том, что в их жизни пошло не так, или о чем-то вроде утреннего восхода солнца. ИИ этого не делают.
Я немного скептически отношусь к тому, что у ИИ будет такой жизненный опыт, чтобы он мог сообщать людям что-то значимое.
Подробнее:
Может ли искусственный интеллект самым большим вкладом в музыку создавать новые жанры?Я думаю, что здесь произойдет большой сдвиг — смешение различных музыкальных стилей.В настоящее время проводятся исследования, в которых содержание одного вида музыки сочетается с другим стилем, одновременно исследуя, возможно, три или четыре разных жанра.
Несмотря на то, что сложно попробовать эти мэшапы в студии с настоящими музыкантами, ИИ может легко попробовать миллион различных комбинаций жанров.
Может ли ИИ в конечном итоге лишить работы музыкантов-людей?Люди говорят это с каждым внедрением новых технологий в музыку.С изобретением граммофона, например, все были обеспокоены, говоря, что это будет ужасно и конец музыке. Но, конечно, это было не так. Это был просто другой способ употребления музыки.
AI может позволить большему количеству людей создавать музыку, потому что теперь намного проще сделать профессионально звучащий сингл даже на своем телефоне, чем это было 10 или 20 лет назад.
Женщина взаимодействует с музыкальным дирижером AI во время Интернет-конференции 2020 года в Учжене, провинция Чжэцзян, Китай.© Гетти
На данный момент ИИ похож на инструмент. Но в ближайшем будущем он может стать одним из соавторов. Может быть, это поможет вам, предложив некоторые партии баса или предложив несколько идей для разных текстов, которые вы, возможно, захотите использовать в зависимости от жанров, которые вам нравятся.
Я думаю, что совместное творчество ИИ и человека — как равных творческих партнеров — будет действительно ценной частью этого.
Насколько хорошо ИИ воспроизводит человеческое пение? В наши дниAI может создать довольно убедительную симуляцию человеческого голоса.Но настоящий вопрос в том, почему вы все равно хотите, чтобы это звучало как человеческое. Почему ИИ не должен звучать как ИИ, что бы это ни было? Вот что мне действительно интересно.
Я думаю, мы слишком зациклены на том, чтобы машины звучали как люди. Было бы гораздо интереснее исследовать, как бы он высказал свой собственный голос, если бы у него был выбор.
Какие еще технологии будущего могут изменить музыкальную индустрию?Обожаю музыкальных роботов. Робот, который может воспроизводить музыку, был мечтой многих на протяжении более века.И в последние, может быть, пять или десять лет, все действительно начало складываться, когда у вас есть ИИ, который может реагировать в режиме реального времени, и у вас есть роботы, которые действительно могут двигаться очень человечно и эмоционально.
Самое интересное — это не только музыка, которую они делают, но и жесты, которые сочетаются с музыкой. Они могут кивать или стучать ногами в такт. Сейчас люди создают роботов, с которыми можно играть в режиме реального времени в ситуации, подобной группе.
Что действительно интересно мне, так это то, что эта комбинация технологий объединилась, и мы действительно можем почувствовать себя живым существом, которым мы играем музыку.
Могут ли в будущем сольные исполнители гастролировать по всему миру с группой роботов?Да, конечно. Я думаю, это было бы здорово! Будет интересно посмотреть, что об этом думает публика. На данный момент довольно весело играть музыкантом с роботом. Но разве действительно весело наблюдать за выступлениями роботов? Может быть это. Вы только посмотрите на Daft Punk!
О нашем эксперте, профессоре Нике Брайан-КиннсеНик Брайан-Киннс — директор Центра медиа и художественных технологий Лондонского университета королевы Марии и профессор интерактивного дизайна.Он также является соисследователем в Центре подготовки докторантов UKRI в области искусственного интеллекта для музыки и старшим членом Ассоциации вычислительной техники.
Подробнее о музыке:
Первая в мире рождественская песня, созданная искусственным интеллектом — это материал кошмаров
Тексты многих праздничных песен сливаются с фоном, окутанные бубенцами и рождественским звоном, неотличимые друг от друга. Но, по крайней мере, каждая песнь, которую пели у костра, была написана человеком — до сих пор.
Исследователи из Университета Торонто обучили повторяющуюся нейронную сеть, тип сложного искусственного интеллекта (ИИ), чтобы написать песню, вдохновленную изображением рождественской елки. Послушайте его выше и посмотрите, не охладит ли он вас больше, чем морозный зимний вечер.
В статье, находящейся на рассмотрении конференции, авторы объясняют, как они научили ИИ сочинять мелодии, дав ему 100 часов онлайн-музыки. Они также предоставили программе тысячи изображений с подписями, чтобы она могла связывать определенные слова с визуальными образцами, а затем создавать тексты и музыку, когда предоставляется изображение.
«Вместо того, чтобы покупать караоке с определенными треками на нем, вы можете создать свое собственное караоке дома, добавив несколько интересных фотографий и предложив машине генерировать музыку для вас», — сказал Санья Фидлер, один из авторов газеты. Хранитель. «Я думаю, что у него безграничные возможности».
Как песня? Что ж, это начинается празднично, хотя и немного мягко, но все быстро становится тревожным. Возможно, направляя дух Диккенса, ИИ поет: «Я всегда был там всю оставшуюся жизнь», предполагая, что призрак в машине превзошел восприятие времени, которое мы держим в маленьких мешках с мясом.Но мы можем заглянуть в истинный страх, когда завеса радостного настроения ненадолго приподнимается, и песня позволяет проскочить что-то зловещее в зале.
Обеспокоены тем, что песенное искусство станет еще одной работой, которая отойдет на второй план революции автоматизации? Мы, люди, довольно искусны в написании ужасных новинок рождественской музыки — в конце концов, Элмо и Пэтси были настоящими людьми, а не (насколько нам известно) демонами пыток, несмотря на то, что они навязывали публике «Бабушку сбил олень».
Таким образом, можно с уверенностью сказать, что искусственному интеллекту еще предстоит пройти путь, прежде чем он подойдет нам в плане написания идеальной мелодии.Фактически, это еще одна попытка ИИ создать повествовательную песню на основе изображения:
Тем не менее, если это худшее, что приготовили для нас роботы, все будет в порядке. По крайней мере, это не гладкий джаз.
Слушайте «новую» песню нирваны, написанную с помощью искусственного интеллекта
С момента смерти Курта Кобейна в 1994 году поклонники Nirvana строили гипотезы о музыке, которую он написал бы, если бы был жив. Но кроме «Ты знаешь, что ты прав», шершавой, мучительной медитации о замешательстве, которую Нирвана записала за несколько месяцев до его самоубийства, и нескольких комментариев, которые он рассказал доверенным лицам о возможном сотрудничестве с Р.Майкл Стипе из E.M., или, идя полностью в одиночку, он в основном оставлял за собой вопросительные знаки.
Теперь организация создала «новую» песню Nirvana, используя программное обеспечение с искусственным интеллектом, чтобы приблизиться к написанию песен певца-гитариста. Гитарные риффы варьируются от тихих, в стиле «Come as You Are» до яростных, Bleach fury à la «Scoff». И такие тексты, как «Солнце светит тебе, но я не знаю как», и удивительно гимновый припев: «Мне все равно / я чувствую себя одним, утонувшим на солнце», несет в себе вызывающие воспоминания качества Кобейна. .
Но кроме вокала — работы фронтмена трибьют-группы Nirvana Эрика Хогана — создатели песни говорят, что почти все в песне, от оборотов фраз до безрассудного исполнения на гитаре, — дело рук компьютеров. Их цель — привлечь внимание к трагедии самоубийства Кобейна и к тому, как живые музыканты могут помочь справиться с депрессией.
Мелодия под названием «Drowned in the Sun» является частью Lost Tapes of the 27 Club, проекта с песнями, написанными и в основном исполненными на машинах в стилях других музыкантов, умерших в 27 лет: Джими Хендрикса, Джима Моррисона и Эми Уайнхаус.Каждый трек является результатом программ AI, которые анализируют до 30 песен каждого исполнителя и детально изучают вокальные мелодии треков, смену аккордов, гитарные риффы и соло, паттерны ударных и тексты, чтобы угадать, как будут звучать их «новые» композиции. Этот проект является результатом работы организации Over the Bridge из Торонто, которая помогает представителям музыкальной индустрии бороться с психическими заболеваниями.
«Утонувшие на солнце» (В стиле Нирвана)
«Что, если бы у всех этих любимых нами музыкантов была психическая поддержка?» — говорит Шон О’Коннор, который входит в совет директоров Over the Bridge, а также работает креативным директором рекламного агентства Rethink.«Каким-то образом в музыкальной индустрии [депрессия] нормализуется и романтизируется… Их музыка воспринимается как подлинное страдание».
Для создания песен О’Коннор и его сотрудники привлекли программу Google Magenta для искусственного интеллекта, которая учится сочинять музыку в стиле определенных исполнителей, анализируя их работы. Ранее Sony использовала программное обеспечение для создания «новой» песни Beatles, а группа Yacht использовала его для написания своего альбома 2019 года Chain Tripping .
Для проекта Lost Tapes Magenta проанализировала песни исполнителей в виде файлов MIDI, которые работают аналогично прокрутке плеера и фортепиано, переводя высоту звука и ритм в цифровой код, который можно передать через синтезатор для воссоздания песни.После изучения выбранных каждым исполнителем нот, ритмических причуд и предпочтений гармонии в файле MIDI, компьютер создает новую музыку, которую сотрудники могут изучить, чтобы выбрать лучшие моменты.
«Чем больше MIDI-файлов вы введете, тем лучше», — говорит О’Коннор. «Итак, мы взяли от 20 до 30 песен от каждого из наших артистов в виде файлов MIDI, разбили их на хук, соло, вокальную мелодию или ритм-гитару и пропустили их по очереди. Если вы пропустите целые песни, [программа] начнет действительно путаться в том, как [она] должна звучать.Но если у вас есть просто куча риффов, вы получите около пяти минут новых риффов, написанных искусственным интеллектом, 90 процентов из которых действительно плохие и неслыханные. Так что вы начинаете прислушиваться и просто находите небольшие интересные моменты ».
О’Коннор и его команда использовали аналогичный процесс для текстов песен, используя общую программу искусственного интеллекта, называемую искусственной нейронной сетью. Они могли ввести слова исполнителя и начать с нескольких слов, а программа угадывала ритм и тон стиха, чтобы завершить его.«Это было много проб и ошибок», — говорит О’Коннор, добавляя, что команда исследовала «страницы и страницы» текстов на предмет фраз, которые слогово соответствуют вокальным мелодиям, создаваемым Magenta.
«Человек, которого я знаю» (в стиле Эми Уайнхаус)
После того, как композиции были на месте, аудио-хаус расположил все различные части, чтобы пробудить в памяти музыканта. «Многие инструменты были MIDI с добавлением различных эффектов», — говорит О’Коннор о готовых записях.Потом начали набирать певцов. «Все, кого мы пригласили, по большей части работали трибьют-исполнителями для этих групп, поэтому они могли придать интонации и сделать звучание максимально реалистичным, — говорит О’Коннор.
Эрик Хоган возглавлял Atlanta Nevermind: The Ultimate Tribute to Nirvana в течение последних шести лет. Группа начинала как разовое развлечение на Хеллоуин; это повод для Хогана и его друзей исполнить трибьют-сеты Foo Fighters, Stone Temple Pilots и Nirvana.Но когда они увидели огромную реакцию, вызванную их сетом Nirvana, они перешли на грандж. Когда команда Over the Bridge попросила его спеть на «Drowned in the Sun», он подумал, что проект звучит невероятно (в самом прямом смысле этого слова) и круто. «После разговора я все еще не думал, что это правда», — говорит он. «А потом они прислали мне файлы и деньги».
Когда он впервые услышал музыку, он был ошеломлен. «Я подумал:« Я не умею [петь] это », — вспоминает он.«Мне пришлось заставить парня, который придумал трек AI, бормотать и напевать [мелодию]. Было бы странно предполагать, что сделает [Кобейн]. Они должны были дать мне небольшую дорожную карту, и после этого все было в порядке ».
О’Коннор и его сотрудники потратили около года на исследования и разработку песен и еще шесть месяцев на завершение записи. В процессе работы они разыскивали суперфанов артистов, чтобы помочь себе в борьбе с потенциальным плагиатом. Они беспокоились, что мелодия в стиле Doors «The Roads Are Alive» может звучать слишком похоже на «Peace Frog» той группы, но в конечном итоге решили, что это не так.«Звукорежиссер взял« Peace Frog »и проиграл нам, — говорит О’Коннор. «Он такой:« Это то, что делает «Peace Frog»; вот что это делает ». Это другое. Хорошо, теперь нам это удобно «.
«Дороги живы» (В стиле Дверей)
Nirvana оказалась одним из самых сложных артистов для машин. В то время как такой артист, как Хендрикс, часто создавал такие песни, как «Purple Haze» и «Fire», с легко определяемыми риффами, Кобейн часто играл коренастые, панк-последовательности аккордов, которые сбивали с толку компьютеры.«Вы, как правило, получали стену звука», — говорит О’Коннор о вдохновленной нирваной музыке, созданной Magenta. «Во всех их песнях меньше идентифицируемой общей нити, чтобы дать вам этот большой кусок каталога, на котором машина могла бы просто учиться и создавать что-то новое».
«[« Drowned in the Sun »] достаточно точен, чтобы дать вам атмосферу [нирваны], но не настолько точен, чтобы получить письмо о прекращении и воздержании», — утверждает Хоган. «Если вы посмотрите на последний релиз Nirvana без цитирования, который звучал как« You Know You’re Right », то в нем есть такая же атмосфера.Курт просто писал все, что черт возьми, он хотел написать. И если ему это нравилось, то это была песня Нирваны. Я слышу определенные вещи в аранжировке [«Drowned in the Sun»], например: «Хорошо, это что-то вроде атмосферы In Utero прямо здесь или Nevermind прямо здесь. … Я действительно понял его ИИ ».
Хоган говорит, что ему особенно понравились тексты, сочиненные компьютером. По его мнению, слова Кобейна всегда были «своего рода мешаниной», но он считает, что эти тексты более прямые, не упуская из виду типичные послания Кобейна.«Это казалось законченной мыслью», — говорит он.
«В песне говорится:« Я чудак, но мне это нравится », — говорит он. «Это полный Курт Кобейн. Настроение — именно то, что он сказал бы. «Солнце светит тебе, но я не знаю как» — это великий . По сути, из песни я получаю следующее: «Я провалился, а ты — провалился». Разница в том, что меня это устраивает, а тебя нет ». (Когда Хоган услышал музыку, он предложил сыграть на гитаре сам, но продюсеры отказались, выбрав машину.)
Так является ли «Утопление в Солнце» своего рода творением Франкенштейна, существующим вопреки Богу и вселенной? «Я не знаю, лучший ли я парень, с которым можно поговорить об этике», — смеется Хоган. «То есть я езжу по стране, притворяясь кем-то.
«Ты собираешься убить меня» (в стиле Джими Хендрикса)
«Я думаю, у вас будет много людей, которые будут очернять это и будут смотреть на это так:« О, это смерть настоящей музыки », — продолжает он.«Но меня это полностью устраивает. Я думаю, что это довольно круто, если использовать его как инструмент. Я не знаю, что будет в будущем с юридической точки зрения. Как только вы начнете двигаться к тому месту, где он начинает звучать действительно хорошо, возможно, тогда у вас возникнут проблемы с этим ».
Over the Bridge стремится просто повысить осведомленность о ресурсах психического здоровья; У организации есть страница в Facebook, которая предлагает поддержку, а также сеансы и семинары Zoom, чтобы обучить художников и заставить их чувствовать себя менее одинокими.(У них нет планов продавать треки.) «Иногда просто признания одного человека, говорящего:« Я чувствую то же самое, что и ты », достаточно, чтобы люди хотя бы почувствовали, что у них есть какие-то чувства. поддержка », — говорит Майкл Скривен, представитель Lemmon Entertainment, генеральный директор которого входит в совет директоров Over the Bridge.
Скривен надеется, что этот проект также повысит осведомленность о том, сколько работы тратится на музыку с искусственным интеллектом. «Чрезмерное количество человеческих рук в начале, середине и конце, чтобы создать что-то подобное, — говорит он.«Многие люди могут подумать, что [ИИ] в какой-то момент заменит музыкантов, но на данный момент количество людей, необходимое для того, чтобы добраться до точки, в которой песня станет доступной для прослушивания, на самом деле довольно велико». Каждая песня требовала работы О’Коннора, техника Magenta, музыкального продюсера, звукорежиссера и вокалистов. «Мы не собираемся нажимать кнопку и заменять этих художников», — говорит О’Коннор.
«Я надеюсь [люди, перешедшие через мост] углубятся в ИИ», — говорит Хоган. «В этой категории вы можете сделать гораздо больше.”
Если вы боретесь с мыслями о самоповреждении, обратитесь к Национальной линии помощи по предотвращению самоубийств: 1-800-273-8255. Вы также можете перейти в строку Crisis Text Line, отправив текстовое сообщение РАЗГОВОР на номер 741741.
Что делает художника в век алгоритмов?
И что-то вроде инженера во мне говорит: хорошо. Посмотрите, что сделал Google. Это простой вид движка MIDI-генерации, где они взяли все произведения Баха, и он может выплевывать [баховские] фуги.Поскольку Бах написал так много фуг, он отличный пример. Кроме того, он отец современной гармонии. Музыковеды слушают некоторые из этих фуг Google Magenta и не могут отличить их от оригинальных произведений Баха. Опять же, это заставляет задуматься о том, что представляет собой художник.
Я одновременно взволнован и испытываю невероятный трепет по поводу этого пространства, в которое мы расширяемся. Может быть, я хочу задать меньший вопрос: «Мы можем, но должны ли мы?» и многое другое «Как мы делаем это ответственно, ведь это происходит?»
Прямо сейчас есть компании, которые используют что-то вроде Spotify или YouTube для обучения своих моделей с живыми художниками, чьи работы защищены авторским правом.Но компаниям разрешено брать чью-то работу и обучать на ней моделей прямо сейчас. Должны ли мы это делать? Или мы должны сначала поговорить с самими артистами? Я считаю, что должны быть созданы защитные механизмы для художников, программистов, музыкантов.
С другой стороны, есть ли потенциальные преимущества у искусства как учебного набора? Существуют ли способы использования технологий в музыке, чтобы помочь преодолеть барьеры, создать возможности, повысить доступность?
Я разделил искусственный интеллект на две категории: генеративный и вспомогательный.Есть технологии, которые будут делать что-то за нас или делать что-то автономно, а есть вещи, которые помогут нам в нашей повседневной жизни. Я безумно оптимистично отношусь к идее вспомогательных и адаптивных технологий искусственного интеллекта, расширяющих возможности всех, для художников, художников, поэтов, даже для актеров и актеров озвучивания, для музыкантов.
Представьте, если бы мы могли превратить кого-то, кого я люблю, например Принца, в тренировочную группу. А также его права на интеллектуальную собственность принадлежат, и его имущество справедливо оплачивается, не так ли? Все «i» отмечены точками, а «t» перечеркнуты.И из этого тренировочного набора ИИ мог создавать новую музыку. И тогда артист может быть везде и сразу. Это увеличило бы доступность художника и стало бы совершенно революционным источником дохода для художников. Например, у нас были бы эти адаптивные работы, соответствующие контексту повседневной жизни людей, тому, что они делают: их любимые художники поют им, разговаривают с ними, рисуют для них в реальном времени. Я надеюсь, что мы там приземлимся.
Итак, возможно, у меня может быть алгоритм, производящий музыку весь день, которая звучит как артист, которого я фанат, и состояние этого артиста могло бы быть должным образом признано и компенсировано.
Верно!
Это дает нам GENESIS.JSON . Вы можете объяснить, как это работает?
Самое крутое в этом — это живое произведение искусства, которое теперь навсегда живет в блокчейне. Он будет жить там до конца интернета. И это доступно каждому. И есть токенизированное происхождение для одного владельца.